Introduction
Abordons ici, un peu plus en détails, la consommation énergétique d’un système informatique GNU/Linux. C’est un sujet qui me semble assez important compte tenu des problématiques énergétiques qui se trouvaient souvent écartées voire délaissées des raisonnements décisionnaires. Mais maintenant, les bilans carbones des infrastructures informatiques deviennent la norme ( à l’image des hébergeurs qui commencent à justifier leurs bilans 1) ; et c’est là que ce sujet prend son sens : et s’il était possible, à l’image des systèmes embarqués, de réduire périodiquement la consommation des infrastructures ?
L’infrastructure
Dans la suite de cet article, on définit une infrastructure comme le matériel qui compose une machine et la somme des logiciels qui s’exécutent en temps réel dessus. Certains logiciels sont essentiels au fonctionnement global (tels que le kernel et les plateformes de production comme Docker ou Kubernetes) et d’autres non (les autres programmes ou applications d’utilisateur final).
La consommation globale d’un système dépend donc des besoins énergétiques :
- de fonctionnement de chaque composant matériel (CPU, mémoire, écran, carte Wi-Fi,…)
- de la sollicitation plus ou moins intense de ces composants par les différents programmes.
D’un point de vue logiciel, le système est divisé en deux mondes distincts, l’espace kernel et l’espace user. La partie d’exploitation, avec le kernel, est là pour gérer les périphériques, charger les drivers nécessaires, organiser l’ordonnancement des tâches,… Tandis que l’espace dit user contient tous les logiciels spécifiques, les bibliothèques dédiées, etc, qui ne tournent pas dans le kernel.
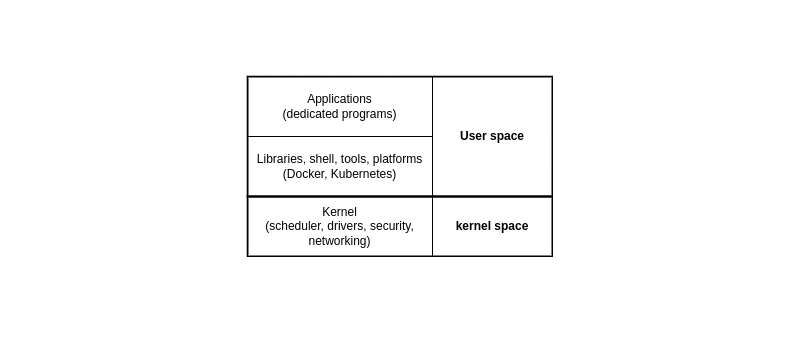
➡ On portera attention au scheduler 2, appartenant au kernel qui est responsable de l’ordonnancement des tâches. Son rôle est central car c’est lui qui alloue aux programmes des intervalles de temps insécables pendant lesquels ils peuvent opérer une partie de leurs instructions. On n’interagira pas directement avec le scheduler, mais connaitre son existence et les différents types de schedulers reste nécessaire pour comprendre les principes de priorités et d’exécution.
Activité
J’ai déjà discuté du lien entre activité et sollicitation énergétique du CPU dans cet article. Les résultats étaient concluants : les temps de calculs alloués aux conteneurs Docker étaient maîtrisés, et leur activité réduite. Mais voyons plus profondément les mécanismes en jeu.
➡ La question est de savoir ici, s’il est possible d’être actif dans la gestion énergétique d’un système, avec une granularité au programme ; dans la mesure où l’humain sait quel ensemble de programmes il lance et pour quels objectifs.
Leviers
À utilisation identique, un programme génère un jeu d’instructions déterminé ; et son empreinte énergétique reste identique dans le même contexte d’utilisation. Pour réduire l’empreinte énergétique, il faut réduire le jeu d’instructions sur la période d’observation, et pour cela deux pistes peuvent être suivies.
- Penser l’architecture du logiciel en incluant des modes de fonctionnement dégradés afin de réduire le code sous-jacent à exécuter. Cela signifie incorporer, et ce dès l’étape de spécification d’un produit, ces différents modes.
- Brider l’exécution du programme au niveau système ou plateforme : limiter au programme sa possibilité d’exécuter ses instructions. Ce procédé peut facilement se généraliser, même si l’expérience utilisateur s’en trouvera impactée.
➡ L’étude de la consommation est très liée à une période d’observation, et pour une même période donnée, réduire la consommation signifie réduire le temps d’activité du programme visé ; par quelconque moyen.
Détermination de l’activité
Commençons d’abord par mesurer l’activité d’un système, puis d’un programme spécifique. Les temps d’activité sont donnés en jiffy, dont la valeur sur mon système est de 100 Hz, soit 10 millisecondes.
$ python3 -c "import os;print(os.sysconf(os.sysconf_names[\"SC_CLK_TCK\"]))"
100
Activité globale
Pour déterminer l’activité globale — le temps que passe le CPU à exécuter des instructions, le kernel propose des statistiques toutes prêtes dans les proc entries, dans un fichier intitulé /proc/stat. Récupérer ces informations et les interpréter sont la base de fonctionnement du logiciel top. Le manuel décrit bien la structure et les données consultables.
$ man 5 proc
[...]
/proc/stat
kernel/system statistics. Varies with architecture. Common entries include:
The amount of time, measured in units of USER_HZ (1/100ths of a second on most architectures, use sysconf(_SC_CLK_TCK) to obtain the right value), that the system ("cpu" line) or the specific CPU ("cpuN" line) spent in various states:
user (1) Time spent in user mode.
nice (2) Time spent in user mode with low priority (nice).
system (3) Time spent in system mode.
idle (4) Time spent in the idle task. This value should be USER_HZ times the second entry in the /proc/uptime pseudo-file.
iowait (since Linux 2.5.41)
(5) Time waiting for I/O to complete. This value is not reliable, for the following reasons:
irq (since Linux 2.6.0)
(6) Time servicing interrupts.
softirq (since Linux 2.6.0)
(7) Time servicing softirqs.
steal (since Linux 2.6.11)
(8) Stolen time, which is the time spent in other operating systems when running in a virtualized environment
guest (since Linux 2.6.24)
(9) Time spent running a virtual CPU for guest operating systems under the control of the Linux kernel.
guest_nice (since Linux 2.6.33)
(10) Time spent running a niced guest (virtual CPU for guest operating systems under the control of the Linux kernel).
[...]
Il suffit de calculer le temps que le système a passé à fonctionner3 4, basé sur le nombre de jiffies écoulé:
Total activité = user + nice + system + idle + iowait + irq + softirq + steal
Ce qui donnera le code Python suivant :
def get_total_jiffies() -> int:
"""
get the absolute total jiffies elapsed
"""
res = 0
with open(os.path.join("/", "proc", "stat"), "r") as stats:
line = stats.readline().strip().replace(" ", " ").split(" ")
# remove guest
del line[9]
del line[8]
jiffies = [ int(i) for i in line[1:] ]
res = sum(jiffies)
return res
Et dont le résultat sera une quantité de jiffies, par exemple 634434, 636475,…
Activité d’un programme
Et pour le cas d’un programme spécifique, on ira consulter le fichier intitulé par le numéro de son pid.
$ man 5 proc
[...]
/proc/[pid]/stat
Status information about the process. This is used by ps(1). It is defined in the kernel source file fs/proc/array.c.
(1) pid %d
The process ID.
(2) comm %s
The filename of the executable, in parentheses
[...]
(14) utime %lu
Amount of time that this process has been scheduled in user mode, measured in clock ticks (divide by sysconf(_SC_CLK_TCK)). This includes guest time, guest_time (time spent run‐
ning a virtual CPU, see below), so that applications that are not aware of the guest time field do not lose that time from their calculations.
(15) stime %lu
Amount of time that this process has been scheduled in kernel mode, measured in clock ticks (divide by sysconf(_SC_CLK_TCK)).
(16) cutime %ld
Amount of time that this process waited-for children have been scheduled in user mode, measured in clock ticks (divide by sysconf(_SC_CLK_TCK)). (See also times(2).) This in‐
cludes guest time, cguest_time (time spent running a virtual CPU, see below).
(17) cstime %ld
Amount of time that this process waited-for children have been scheduled in kernel mode, measured in clock ticks (divide by sysconf(_SC_CLK_TCK)).
(18) priority %ld
[...]
On sera intéressé ici par les valeurs de utime, stime, et cutime, cutime selon si l’on veut également inclure les statistiques des processus enfants.
Total activité processus = utime + stime
Total activité processus avec enfants = utime + stime + cutime + cstime
Ce qui donnera le code Python suivant :
def read_process_jiffies(pid:str, with_children:bool=False) -> int:
"""
get the total process jiffies
(utime, stime, cutime, cstime)
"""
res = 0
with open(os.path.join("/", "proc", pid, "stat"), "r") as stats:
line = stats.readline().split(" ")
res = int(line[13]) + int(line[14])
if with_children:
res = res + int(line[15]) + int(line[16])
return res
Les valeurs calculées seront toujours inférieures à celles du système. Elles sont globales, pour tous les CPU.
➡ On est maintenant capable de calculer le pourcentage d’activité d’un programme : il suffit, sur un intervalle donné de faire le ratio entre temps d’activité du système et le temps d’activité du programme.
Détermination de la consommation
Sur la machine d’étude, le kernel propose des proc entries dédiées à l’utilisation de la batterie : le courant consommé et sa tension. Ces proc entries sont accessibles à ces deux endroits : /sys/class/power_supply/BAT0/current_now et /sys/class/power_supply/BAT0/voltage_now. La puissance est calculée par le produit du courant et de la tension.
Mais regardons la signification de ces valeurs, qui sont mesurées instantanément. En tenant compte de la période d’observation, on pourra pour une meilleure précision des mesures, les lire de manière répétée et en calculer la moyenne.
Consommation globale
La détermination de la consommation globale sera alors établie par l’exemple de script suivant :
def get_total_power(interval:int, sampling:int) -> tuple:
"""
get the average total power of the system
based on battery proc entries
returns: (current, voltage, power)
"""
res = (0, 0, 0)
current_path = "/sys/class/power_supply/BAT0/current_now"
voltage_path = "/sys/class/power_supply/BAT0/voltage_now"
current_values = [0]
voltage_values = [0]
power_values = [0]
delay = float(interval / sampling)
for k in range(sampling):
with open(current_path, "r") as current:
with open(voltage_path, "r") as voltage:
current = int(current.readline())/1000000
voltage = int(voltage.readline())/1000000
current_values.append(current)
voltage_values.append(voltage)
power_values.append(current * voltage, 2)
time.sleep(delay)
res = (round(mean(current_values), 2), round(mean(voltage_values), 2), round(mean(power_values),2))
return res
Cette consommation illustre la puissance nécessaire à toute l’infrastructure sur l’intervalle d’observation.
Consommation d’un programme
C’est là qu’une approximation supplémentaire est nécessaire. Pour estimer la consommation d’un programme, on supposera que dans une certaine mesure la consommation globale de l’infrastructure est équivalente à celle de l’activité CPU globale du système.
Consommation du programme = consommation globale * ratio d activité du programme
C’est bien sûr une estimation car on récupère le niveau de batterie global, sans pour autant utiliser les outils dédiés tels que le fait Scaphandre5 avec RAPL6.
Thanks to this technology it is possible to get the total energy consumption of the CPU, of the consumption per CPU socket, plus in some cases, the consumption of the DRAM controller. In most cases it represents the vast majority of the energy consumption of the machine (except when running GPU intensive workloads, for example).
Ce ne sera pas le cas dans cet article.
➡ On peut dorénavant estimer la consommation d’un programme, estimation qui sera toujours plus juste sur une machine qui a le minimum de périphériques en cours d’utilisation.
Outils de réduction d’activité
Maintenant que l’on est capable de mesurer l’activité d’un programme, d’en estimer son empreinte énergétique, tournons nous sur les moyens de réduction d’activité, et indirectement de consommation.
Priorisation
Il est possible de changer la priorité des processus et les reléguer en fin de liste : le scheduler leur allouera alors moins de temps pour tourner, et donc consommer5. Cela est réalisé avec la commande nice, pour les processus qui sont en scheduling policy SCHED_OTHER (ou SCHED_BATCH). On peut lister les scheduling policies des processus via la commande chrt.
The nice value is an attribute that can be used to influence the CPU scheduler to favor or disfavor a process in scheduling decisions. It affects the scheduling of SCHED_OTHER and SCHED_BATCH (see below) processes. The nice value can be modified using nice(2), setpriority(2), or sched_setattr(2).
$ for pid in $(ps aux | grep -iv pid | tr -s " " | cut -d " " -f2); do chrt -p $pid; done
[...]
stratégie d’ordonnancement actuelle pour le PID 29662 : SCHED_OTHER
priorité de planification actuelle pour le PID 29662 : 0
[...]
Cela peut dans un premier abord être une solution, mais que se passe-t-il si on veut maîtriser de manière déterministe l’allocation énergétique ? Cela n’est pas possible car si les processus de plus haute priorité terminent, le processus étudié se verra utiliser plus de temps de calcul et donc plus de ressources.
➡ La notion de priorité est relative à l’activité instantanée de l’infrastructure, et ne propose pas de limite objective et déterministe.
Utilitaires
On peut se tourner vers un outil Linux très pratique : cpulimit pour réduire l’activité d’un processus, à partir de son numéro de pid. Pour limiter à 50% de CPU un processus, on peut appeler la commande suivante.
$ cpulimit -l 50 -p $PID
Le principe en coulisse est de créer un groupe de processus et d’aller en changer les limites d’exécution 7.
➡ Même si très pratique, il ne gère qu’un processus seulement, et la configuration n’est pas persistante; dès que cpulimit est stoppé, le processus pid reprend son rythme de croisière.
Docker
Dans le monde de la production de logiciels, l’intégration dans Docker est un plus, car elle permet de maîtriser un sous ensemble déterminé de logiciels : ceux qui constituent l’image Docker instanciée. Avec la bibliothèque Python pour Docker8, on peut programmatiquement altérer la configuration système de chaque conteneur qui s’exécute. L’extrait de la documentation mentionne plusieurs paramètres à moduler.
update(**kwargs)
Update resource configuration of the containers.
Parameters
blkio_weight (int) – Block IO (relative weight), between 10 and 1000
cpu_period (int) – Limit CPU CFS (Completely Fair Scheduler) period
cpu_quota (int) – Limit CPU CFS (Completely Fair Scheduler) quota
cpu_shares (int) – CPU shares (relative weight)
cpuset_cpus (str) – CPUs in which to allow execution
cpuset_mems (str) – MEMs in which to allow execution
mem_limit (int or str) – Memory limit
mem_reservation (int or str) – Memory soft limit
memswap_limit (int or str) – Total memory (memory + swap), -1 to disable swap
kernel_memory (int or str) – Kernel memory limit
restart_policy (dict) – Restart policy dictionary
Returns
Dictionary containing a Warnings key.
Return type
(dict)
Raises
docker.errors.APIError – If the server returns an error.
On configurera les paramètres
cpuset_cpus(str) – CPUs in which to allow executioncpu_quota(int) – Limit CPU CFS (Completely Fair Scheduler) quotacpu_period(int) – Limit CPU CFS (Completely Fair Scheduler) period
➡ Avec cette bibliothèque, on va pouvoir étudier la limitation de ressources de conteneurs Docker, qui sont en policy SCHED_OTHER et qui de ce fait sont gérés par le CFS.
Étude
Pour étudier les effets de la réduction, on va lancer un conteneur Docker incorporant l’utilitaire stress, puis on limitera au fur et à mesure son quota de ressources.
def run_stress_container(name:str, cpus:int=1) -> Optional[list]:
"""
run container
"""
client = get_docker_client()
try:
container = client.containers.run(
image="progrium/stress",
command=f"--cpu {cpus}",
name=name,
detach=True,
remove=True,
)
except docker.errors.NotFound:
return None
except docker.errors.ContainerError:
return None
else:
cmd = "pidof stress"
res = subprocess.check_output(cmd, shell=True)
res = str(res.decode("utf-8")).replace("\n", "").split(" ")
return res
En récupérant les différents pid du conteneur, on pourra mesurer leur consommation. Et on stockera dans un fichier CSV les valeurs suivantes :
- PID
- Jiffies globales
- Jiffies du processus
- Ratio d’activité du processus
- Courant moyenné sur l’intervalle de mesure
- Tension moyennée sur l’intervalle de mesure
- Puissance moyennée sur l’intervalle de mesure
- Nombre total de processus sur la machine
- Nombre de processus en scheduling policy
SCHED_FIFO - Nombre de processus en scheduling policy
SCHED_RR - Nombre de processus en scheduling policy
SCHED_OTHER
Le script qui génère ce fichier CSV est accessible ici.
On lance le script avec la commande suivante :
$ python consumption.py -i 2 -N 15 -T 1 -S 1
Avec un intervalle -i de 2 secondes entre deux mesures, 15 boucles -N de mesures avant de limiter l’activité (de 100% à 5%, et de 5% à 100%), avec sollicitation -T d’un CPU sur le CPU -S numéro 1.
Résultats
Voici à quoi ressemble le contenu du fichier CSV. Deux secondes séparent donc deux lignes.
cpu_quota;cpuset_cpus;current;number_of_processes;percentage_process;pid;power;process_jiffies;process_power;processes_fifo;processes_other;processes_rr;total_jiffies;voltage
1.0;1;0.74;314;0.00172;79969;11.77;220;0.0;23;288;0;12780308;15.96
1.0;1;0.74;314;2e-05;79937;11.77;2;0.0;23;288;0;12780337;15.96
1.0;1;0.96;298;25.31646;79969;15.14;260;3.83;23;272;0;1027;15.84
1.0;1;0.96;298;0.0;79937;15.14;0;0.0;23;272;0;1023;15.84
[...]
Activité
Simple thread
On constate, sur ce graphe, que le nombre de jiffies pour ce processus diminue et augmente en fonction du quota que l’on fixe. On commence à 100% de quota, pour diminuer jusqu’à 5%, et remonter à 100%.
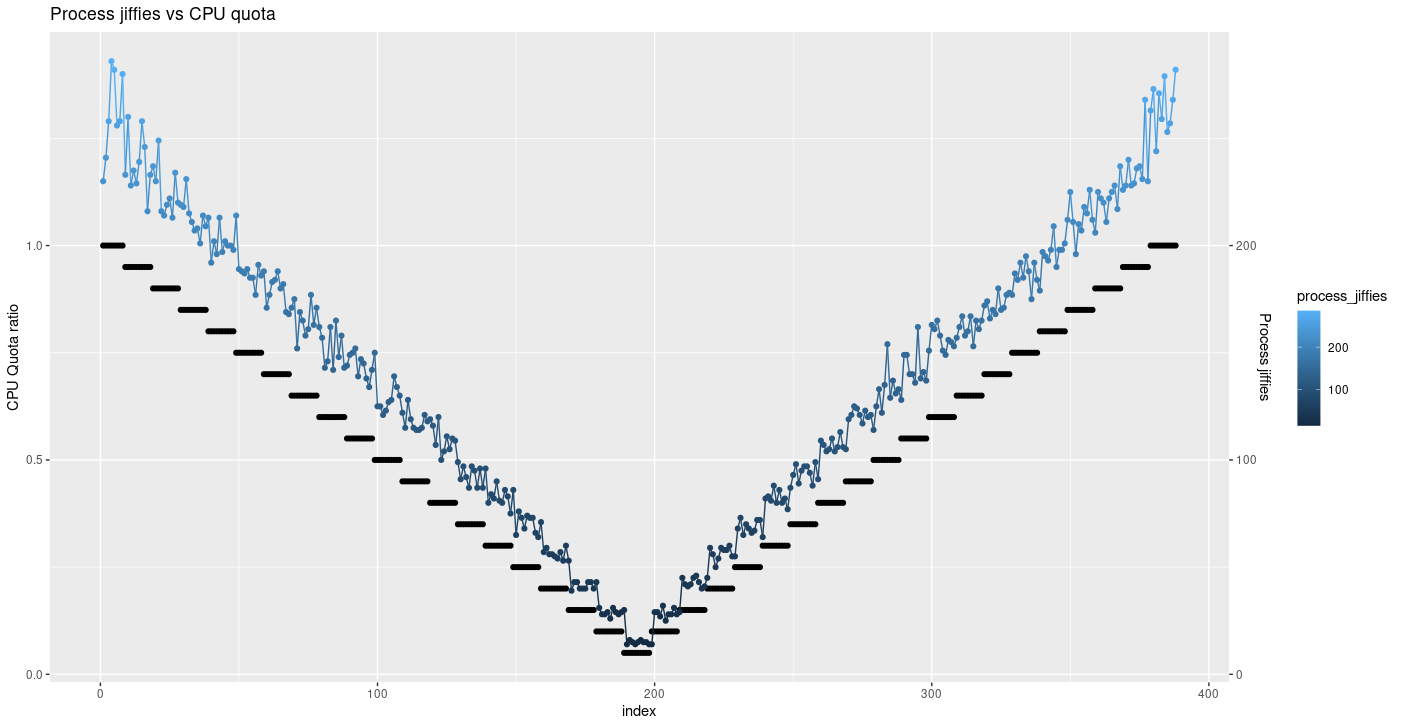
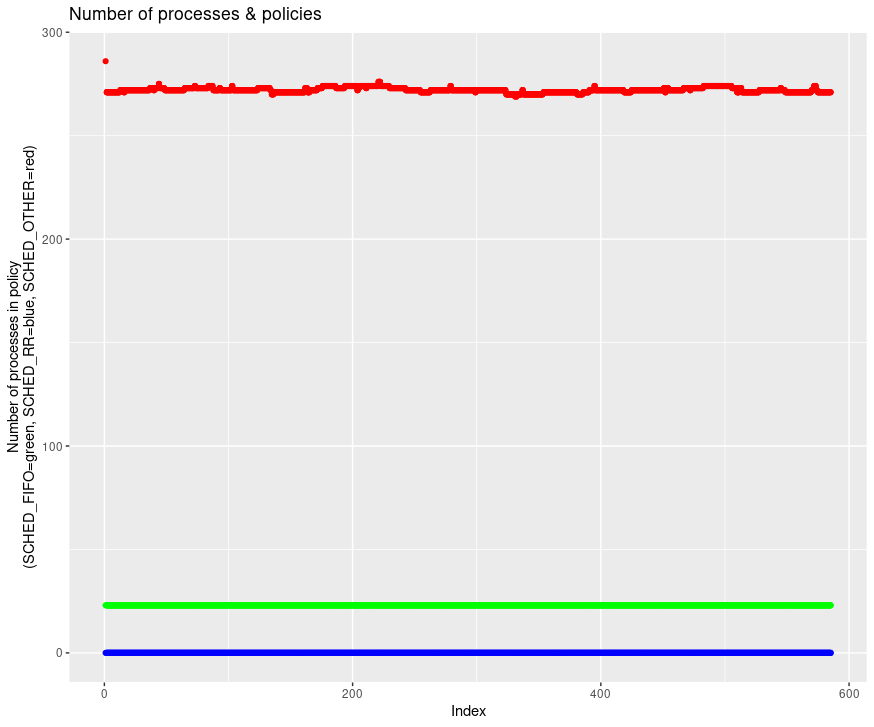
Mais n’oublions pas comment se comporte le scheduler : si le nombre de processus total augmente sur la machine, le nombre de jiffies alloué pour chaque processus va diminuer, pour laisser du temps à chacun d’exécuter ses instructions. Vérifions le nombre de processus sur la période d’étude.
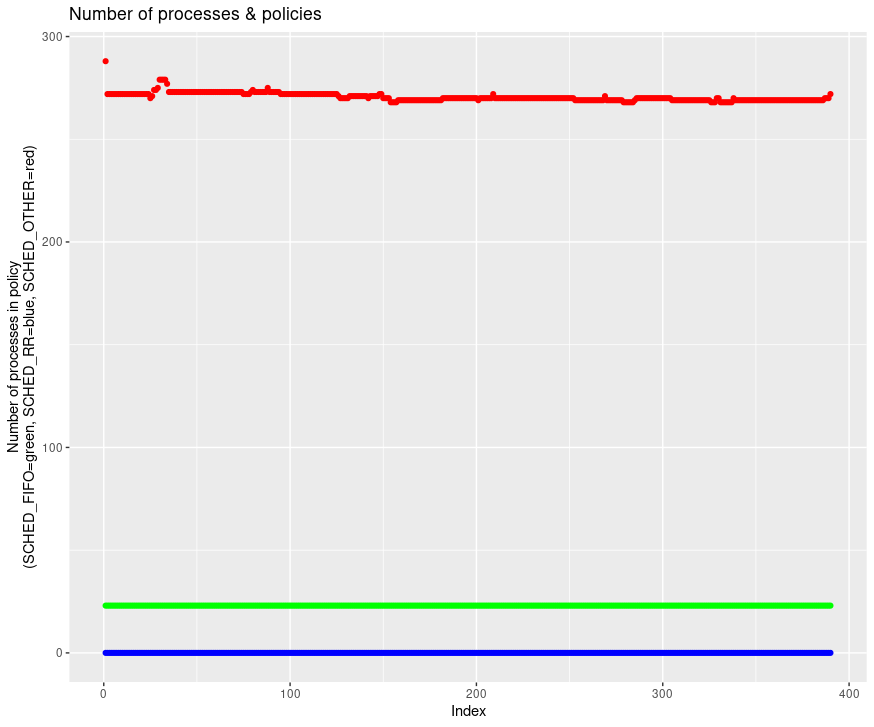
Au premier abord, le nombre semble stable. En comparant également le nombre de processus dans chaque policy, on constate que l’état de la machine est stable et qu’aucun processus en SCHED_FIFO ou SCHED_RR ne vient prendre plus de temps et diminuer l’allocation de jiffies des processus en SCHED_OTHER.
Multiples CPU
On lance maintenant le conteneur de stress simulant 100% d’activité d’un CPU sur 3 cores, avec la commande suivante.
$ python consumption.py -i 2 -N 15 -T 3 -S 0-2
Regardons le résultat.
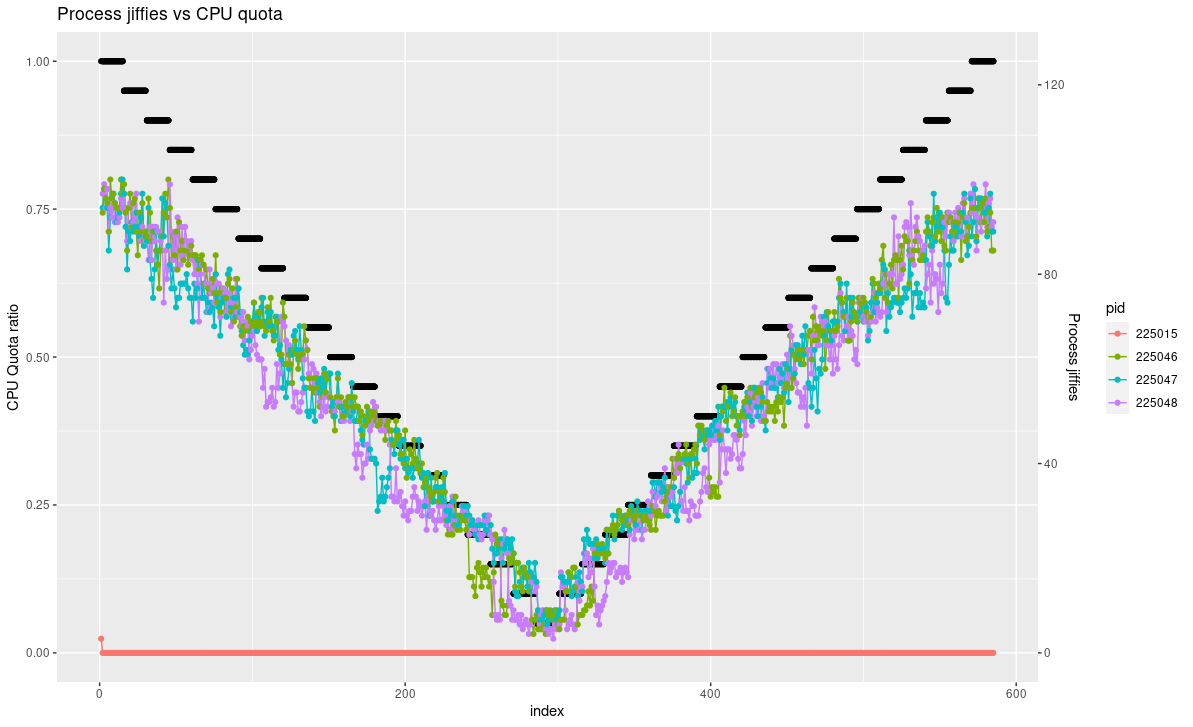
On note bien 4 processus ; le premier est le processus parent, dont l’activité est proche de zéro. La somme des jiffies écoulées par processus respecte bien le rapport 3 par rapport à un seul CPU.
➡ On peut donc conclure que c’est bien nous qui limitons le programme de stress et que ce n’est pas une fortuite coincidence.
Consommation
Simple thread
En reprenant la formule que nous avons proposée, on va pouvoir calculer la consommation du programme de stress.
Consommation du programme = consommation globale * ratio d activité du programme
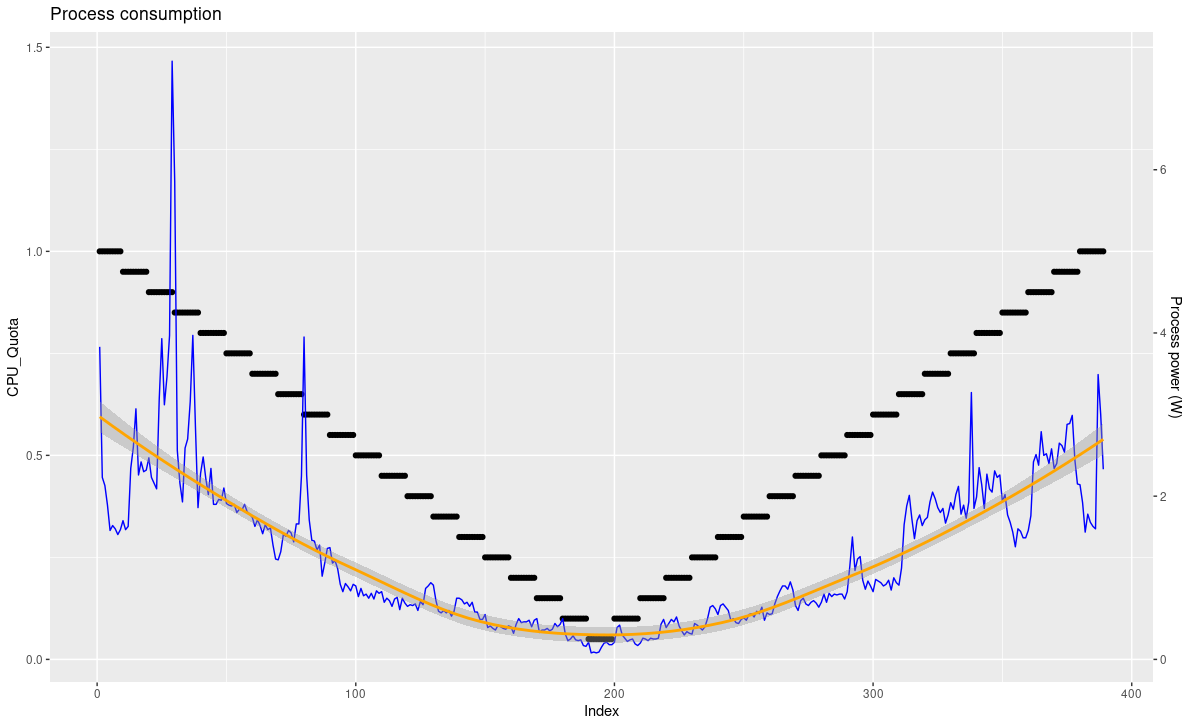
Il est important de noter certaines aberrations possibles, notamment que certains pics de consommation puissent être conséquents à des activités diverses (communication réseau, écriture sur le disque,…) et dans ces cas-là, le réel pourcentage de consommation de ce processus n’est pas juste. On note quand même une tendance qui suit le quota d’activité — cohérent dans la mesure où le pourcentage d’activité CPU diminue.
La consommation globale ne montre pas pour autant de diminution sur l’intervalle d’observation.
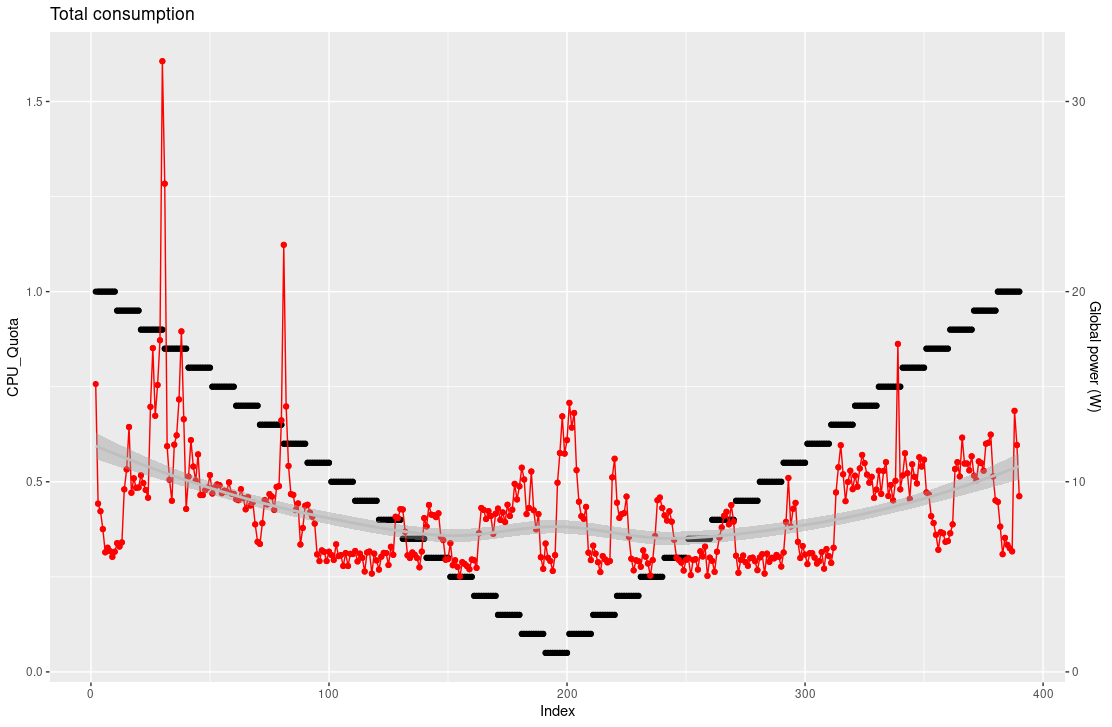
Une raison à cela est que les autres processus de la machine aient momentanément besoin de plus ; ou bien que la limitation d’un seul processus sur les environs 300 sur la machine ne soit pas significative à cette échelle.
Multiples CPU
On retrouve logiquement le rapport 3 qui montre une consommation trois fois moins importante par processus.
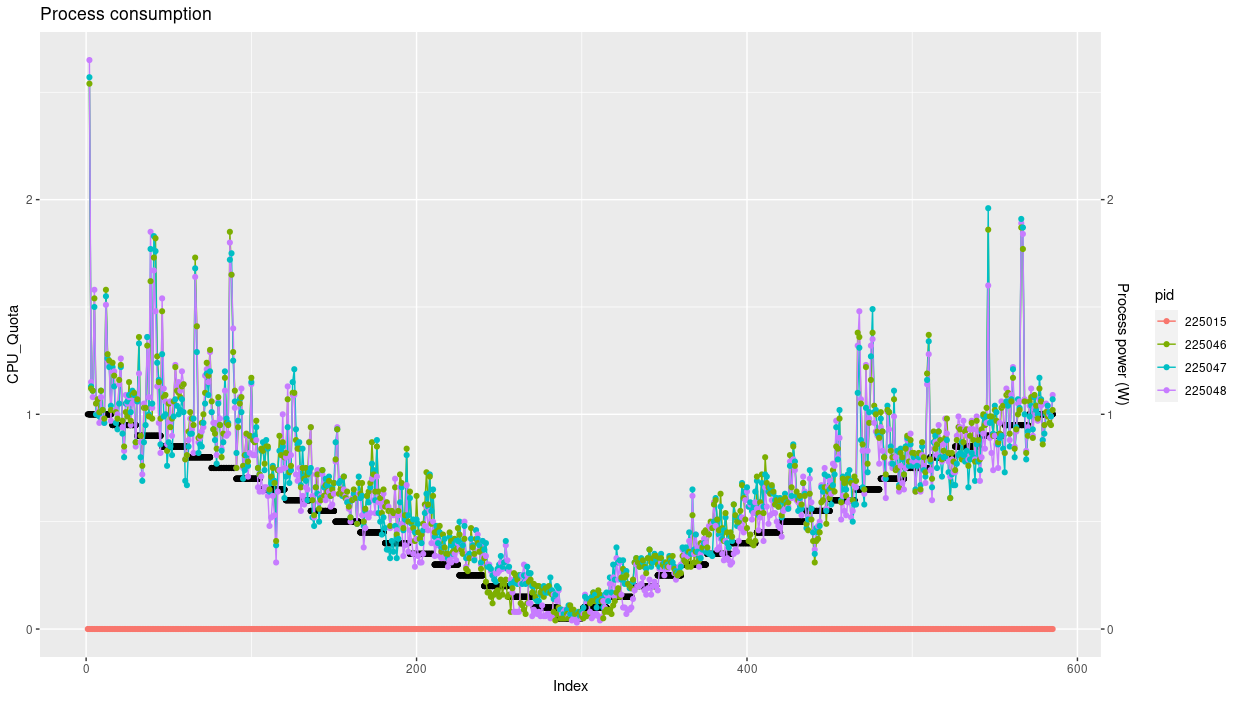
Et de même que la consommation globale avec un simple thread, avec l’occupation de trois cores elle semble rester indépendante du quota de CPU autorisé.
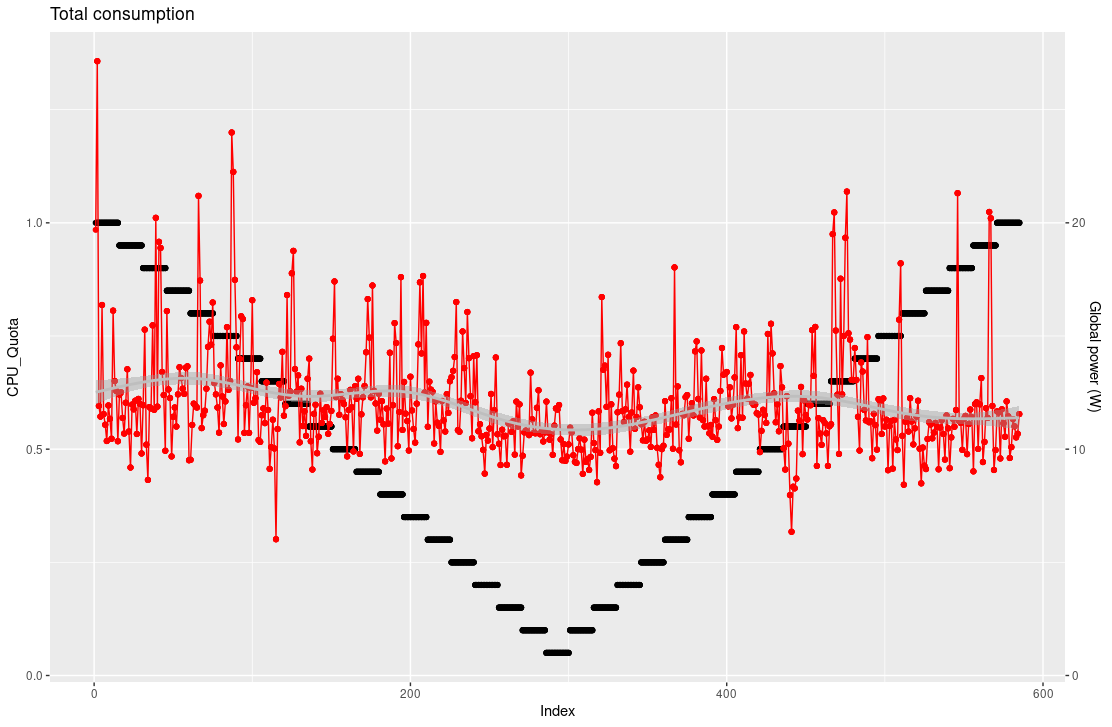
➡ Dans le cadre des suppositions faites pour la consommation, on observe bien une diminution de l’empreinte énergétique du processus, en cohérence avec le calcul lui-même basé sur le ratio d’activité. La demande énergétique globale de l’infrastructure reste quant à elle stable ; mais sans étudier l’intégralité des autes processus et leur nature, il n’est pas possible de statuer et d’en trouver la raison.
Conclusion
On peut déjà commenter sur l’intrication du scheduling et de la consommation du CPU, et que le scheduler reste essentiel pour proposer une porte d’entrée à la gestion d’activité. Le raisonnement derrière le scheduling montre qu’il est très impactant sur l’allocation des ressources et donc sur la consommation. On peut se poser la question suivante : le principe derrière le scheduler standard de Linux (CFS) est-il le meilleur pour appréhender cette thématique de gestion d’énergie ?
Cependant, une constatation semble claire : il est possible de maîtriser les activités des programmes, soit en allant directement changer leurs attributs (via cpulimit par exemple), soit en passant par une plateforme d’administration de programmes (telle que Docker), qui permet surtout une adaptation de la granularité : parfois on voudra maîtriser une application complète, qui est en réalité un sous ensemble de programmes, et non traiter chaque sous programme indépendamment. Pour autant, les mécanismes feront appel in fine au scheduler.
Mais la réponse à cette gestion énergétique ne réside-t-elle pas dans le développement d’une méthode de scheduling adaptée à la gestion énergétique, comme on peut le voir pour les systèmes temps-réel ? Pourrait-on intégrer des modes de fonctionnement dégradés directement dans le kernel et la gestion des périphériques ? Qu’existe-t-il déjà dans le kernel à ce sujet ?
https://corporate.ovhcloud.com/fr/sustainability/environment/ ↩︎
https://www.kernel.org/doc/html/latest/scheduler/sched-design-CFS.html ↩︎
https://stackoverflow.com/questions/5514119/accurately-calculating-cpu-utilization-in-linux-using-proc-stat ↩︎
https://github.com/brgl/busybox/blob/master/procps/top.c#L276 ↩︎
https://hubblo-org.github.io/scaphandre-documentation/explanations/how-scaph-computes-per-process-power-consumption.html#some-details-about-rapl ↩︎
https://github.com/opsengine/cpulimit/blob/f4d2682804931e7aea02a869137344bb5452a3cd/src/cpulimit.c#L189 ↩︎
https://docker-py.readthedocs.io/en/stable/containers.html#docker.models.containers.Container.update ↩︎