Introduction
Le monde numérique et la notion d’identité sont toujours très intriqués. On se rend compte que d’une part, en tant qu’utilisateurs de services numériques on fournit une quantité d’informations personnelles importante. Puis, en creusant un peu, on découvre que l’écosystème économique du monde numérique se base sur nos identités en ligne, et qu’il est difficile d’appréhender ce que nous dévoilons de nous-même. De quelle identité parle-t-on, que cela implique-t-il sur notre présence en ligne ? Tentons de répondre à ces questions.
Tout au long de cet article, on parlera d’identité réelle ou numérique, que nous définirons de la manière suivante :
- Identité réelle : L’identité de l’individu est la reconnaissance de ce qu’il est, par lui-même ou par les autres. Nom, âge, lieu, cercle social, profession, activités,…
- Identité numérique : Somme d’informations qui permet d’identifier de manière unique un utilisateur d’internet.
Pour cela, voyons d’abord la nature de ces données : celles qui sont consciemment partagées de notre part, et les autres. Nous nous intéresserons à leur cycle de vie, leur but et à leur protection. Nous pourrons ensuite statuer sur ce que l’on laisse en ligne après notre passage.
Cataloguer les informations en partage conscient et inconscient permet dans cet argumentaire, de mettre en lumière deux aspects du monde numérique : une divulgation active de notre identité réelle d’une part, et une perméabilité d’accès à notre identité numérique.
Le partage conscient
Nous partageons d’abord des données qui nous concernent en tant qu’individu. Qu’elles soient des documents officiels ou des photos de familles, nous avons conscience de leur existence, et nous les partageons de notre plein gré. Certaines recommandations peuvent être faites sur la manière de partager son propre contenu, mais ce n’est pas le but de cet article.
Fichage d’identité
En tant que citoyen, une partie de notre identité réelle est enregistrée pour des raisons administratives. Par exemple, ayant un passeport biométrique, nos identités sont stockées dans la base de données TES (pour Titres Électroniques Sécurisés). Voici une liste des principales bases de données concernant les citoyens Français, en y ajoutant pour l’exemple un fournisseur d’énergie et un fournisseur d’accès internet.
| Base de données | Description | Contenu | Durée de rétention des données |
|---|---|---|---|
| Titres Électroniques Sécurisés (TES) 1 | Recensement citoyen | Données biométriques, coordonnées et filiation | Adultes : 20 ans. Mineurs : 15 ans |
| Agence nationale des Titres Sécurisés (ANTS) 2 | Réaliser des démarches administratives en ligne | Selon démarche | Conformément à la CNIL 3 |
| Fichier Automatisé des Empreintes Digitales (FAED) 4 | Faciliter notamment la recherche et l’identification des auteurs de crimes et de délits. | Données biométriques, coordonnées et filiation | 25 ans |
| Ameli 5 | Service d’assurance maladie | Identité réelle et historique médical | Conformément à la CNIL 6 |
| Total Énergies 7 | Fournisseur d’énergie, base de données clients | Identités des clients | Conformément à la CNIL 6, détails 8 |
| Orange 9 | Fournisseur d’accès internet, base de données clients | Identités des clients | Conformément à la CNIL 6, détails 10: en fonction de la catégorie des données. |
Note : Un petit mot sur France Connect11, qui n’est pas une base de données, mais un service numérique permettant de prouver notre identité. Il est soumis à la conformité de la CNIL3.
➡ C’est consciemment que l’on laisse les agents administratifs faire leur travail et gérer nos données citoyennes, avec les outils numériques et les bases de données qui sont officiellement utilisés.
Réseaux sociaux
Partager volontairement son quotidien sur les réseaux sociaux facilite l’accès à notre identité réelle. En fonction des paramètres de partage, il est possible que ces données se retrouvent accessibles publiquement via les moteurs de recherche. En tant que citoyens Européens, la réglementation de la CNIL 3 s’applique également aux entreprises derrière les réseaux sociaux.
➡ Sans se concentrer sur ce sujet, une bonne pratique est de partager nos informations en les considérant comme publiques, comme si tout le monde allait les consulter. Car les réseaux sociaux sont en effet le meilleur outil numérique pour informer sur l’identité réelle des utilisateurs !
Le partage inconscient
Vient alors un autre type de données, lié à la mécanique de l’outil numérique lui-même qui, par le principe même de connexion, génère des données. Ces données sont intrinsèques à nos équipements et elles sont partagées sans notre aval — ou presque — sans qu’on en ait conscience.
Mise en situation
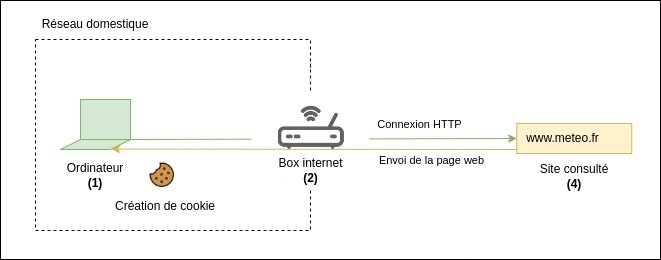
Prenons pour la suite, l’exemple d’une consultation d’un site de prévisions météo, à partir d’un ordinateur à notre domicile.
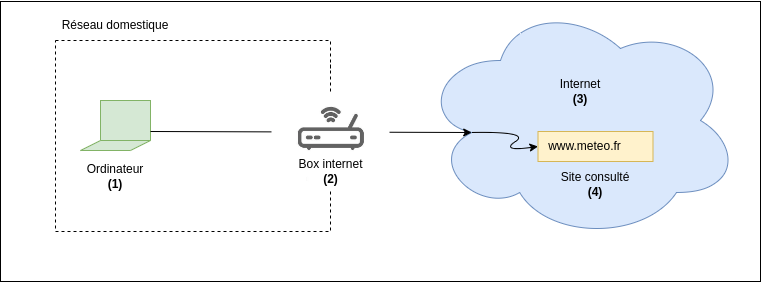
Nous sommes utilisateurs de l’ordinateur (1), souscrivons un abonnement internet et une box (2), et nous nous connectons à internet (3) pour accéder au site web de prévisions météorologiques (4).
⚠️ Par volonté de simplification, certains aspects techniques sont passés sous silence, ou sont rendus quelque peu inexacts en vue d’une compréhension générale.
Les données de connexion
Regardons plus en détails la nature de ces données qui, à la vitesse de la lumière, s’activent pour faire fonctionner le réseau internet. Sommairement, pour récupérer les prévisions météorologiques, notre ordinateur (1) va se connecter à notre box internet (2) de notre domicile qui va prendre en main la connexion, et se connecter au site consulté (4) à travers internet (3).
La connexion se réalise via l’identification par adresses des équipements qui constituent internet. Par définition, la box internet (2) fait partie d’internet, mais pas notre ordinateur, qui reste en aval. Du point de vue d’internet donc, l’adresse de l’ordinateur n’est pas accessible, seule l’adresse de la box l’est car c’est elle qui prend en main cette connexion, qui l’impersonne (voir Notes).
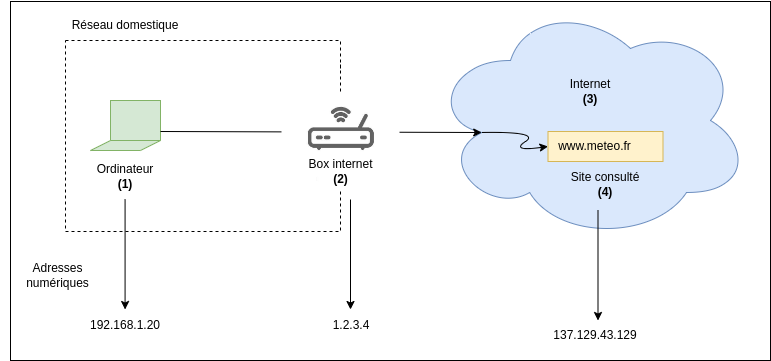
C’est en assignant des adresses numériques (adresses IP) aux équipements qu’ils sont capables de communiquer entre eux. Les conditions d’assignations sont différentes en fonction du type de réseau 12. Dans notre exemple irréel, la connexion sera établie entre l’ordinateur (1) à l’adresse 192.168.1.20 et le site consulté (4) à l’adresse 137.129.43.129, dont la connexion aura été impersonnée par la box dont l’adresse est 1.2.3.4. Les équipements d’aiguillage (voir Notes) qui constituent internet (3) sont là pour physiquement orienter la connexion vers le site consulté, ils agissent comme des relais.
En réalité, la connexion est relayée par de multiples équipements, eux aussi pourvus d’adresse IP. Dans le schéma, ils ne sont pas visibles mais sont bien présents dans l’écosystème internet (3).
Si l’on trace la route de la connexion en utilisant le logiciel traceroute permettant de lister les trente premiers relais vers le site web (4), on obtient le résultat suivant :
$ traceroute meteo.fr
traceroute to meteo.fr (137.129.43.129), 30 hops max, 60 byte packets
1 box.domestique (192.168.1.1) 3.548 ms 3.477 ms 3.458 ms
2 10.169.243.5 (10.169.243.5) 28.335 ms 28.316 ms 28.297 ms
3 10.125.115.83 (10.125.115.83) 37.196 ms 37.179 ms 37.162 ms
4 10.125.120.50 (10.125.120.50) 37.198 ms 37.183 ms 37.167 ms
5 * * *
6 212.194.170.0 (212.194.170.0) 46.863 ms 38.567 ms 44.280 ms
7 be5.cbr01-cro.net.bbox.fr (212.194.171.141) 50.060 ms 27.983 ms 34.350 ms
8 * * *
9 * * *
10 206.96.106.212.in-addr.arpa.celeste.fr (212.106.96.206) 56.064 ms 56.553 ms 56.032 ms
11 7.96.106.212.in-addr.arpa.celeste.fr (212.106.96.7) 56.542 ms 56.526 ms 56.480 ms
12 149.96.106.212.in-addr.arpa.celeste.fr (212.106.96.149) 58.730 ms * *
13 * * *
14 * * *
[...]
30 * * *
Il se trouve que le nom de domaine meteo.fr existe et pointe vers le site web de https://meteofrance.com. Les * * * indiquent que l’information n’a pas pu être récupérée.
On note bien les différents relais, qui sont déjà assez nombreux. Les temps en millisecondes informent sur le temps de réponse de chaque relai.
Parmi toutes ces informations et adresses IP, c’est grâce à celle de notre box (2) que nous partageons, sans le vouloir, notre position géographique globale. En effet, en inspectant les détails avec des sites web d’analyse 13 on peut remonter à notre position. En voici un exemple.
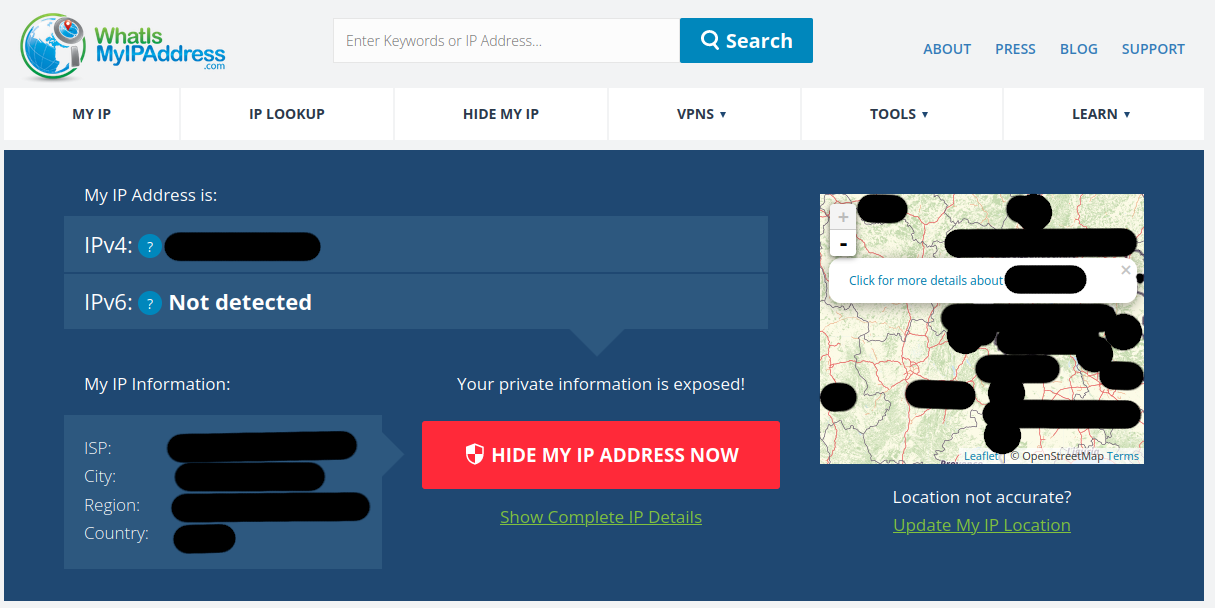 Les informations consultables sont :
Les informations consultables sont :
- ISP : le fournisseur d’accès internet,
- City : la ville,
- Region : la région locale,
- Country : le pays.
➡ Une première étape d’identification, même peu précise, devient accessible. Dans cette situation, nous n’avons pas de contrôle sur la diffusion de cette information ; c’est l’infrastructure elle-même qui semble trop bavarde. Mais en même temps, est-ce anormal ? Il est nécessaire d’adresser les équipements pour qu’ils communiquent entre eux et sans la possibilité de connaitre leur place au sein du réseau qu’est internet, la détection d’erreur et la maintenance en seraient difficiles voire impossibles.
Les noms de domaines
Un second principe régit notre interaction à internet et ses nombreux sites web dont il est constitué. Les noms de domaines établissent une correspondance entre les adresses numériques et un nom facile à lire et se remémorer : c’est bien utile pour nos mémoires. Il est plus simple de se souvenir du nom de domaine d’un site tel que www.meteo.fr que son adresse numérique 137.129.43.129.
Des bases de données (5) sont donc tenues, en temps réel, de tenir à jour ces correspondances. Elles sont appelées base de données DNS (pour Domain Name System) ou encore serveurs DNS. Notre ordinateur (1) va donc leur demander la correspondance numérique du site à consulter www.meteo.fr. Elles vont lui renvoyer son adresse numérique 137.129.43.129, et à ce moment-là, la connexion pourra s’initier.
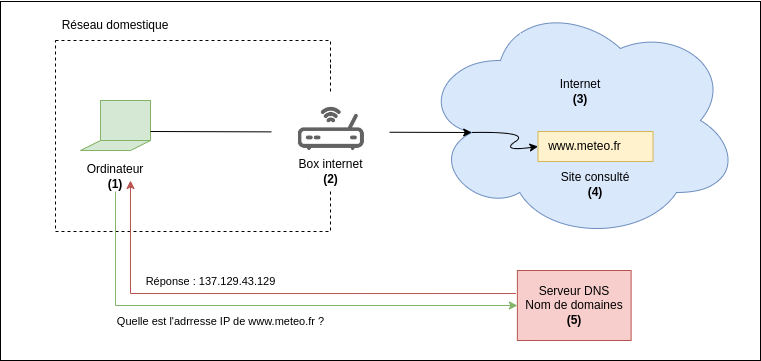
En quoi cela informe sur notre identité d’utilisateurs ? Et bien en enregistrant sur la durée les demandes de correspondances, la base de données DNS sera capable d’observer celles émanant de la box (2) dont l’adresse IP est 1.2.3.4 et en analyser le contenu. Elle pourra forger un profil théorique de l’adresse IP 1.2.3.4 : visites quotidiennes sur un site de sport, consultations de journaux d’actualités français,… et en tirer des conclusions statistiques quant à l’identité réelle de 1.2.3.4.
Des sites web sont accessibles pour consulter ces correspondances 14. Nous pouvons écrire un nom de domaine et voir son adresse IP correspondante.
➡ C’est encore via l’infrastructure elle-même que les utilisateurs peuvent être suivis. Un acteur malveillant peut grâce à ces informations, établir un profil utilisateur. On désigne cette pratique d’identification via l’expression anglaise profiling 15.
Le User Agent HTTP
Lors d’une visite sur un site web, de multiples informations sont échangées. Les données de connexion déjà, puis les données liées à l’écosystème web.
On en revient au mécanisme de fonctionnement des sites web, qui se construit sur celui d’internet. Le mécanisme d’échange de données est tributaire d’un protocole connu : le protocole HTTP (pour Hypertext Transfer Protocol). Ce protocole, par définition définit les informations échangées pour naviguer sur les sites web.
L’équipement utilisé — notre ordinateur dans notre exemple – va communiquer naturellement une partie de son identité logicielle en établissant la connexion HTTP. Cette partie est appelé l’agent utilisateur ou User Agent en anglais. Elle informe sur le navigateur utilisé et l’ordinateur en lui-même. En accédant à des services en ligne 16, on peut consulter notre propre User Agent.
En voici un exemple que nous allons décortiquer.
User-Agent: Mozilla/5.0 (Windows NT 10.0; rv:110.0) Gecko/20100101 Firefox/110.0
Mozilla/5.0informe de la compatibilité avec Mozilla,Windows NT 10.0est la plateforme sur laquelle le navigateur tourne : Windows dans ce cas,rv:110.0correspond à la version utilisée de Gecko,Gecko/20100101indique que le navigateur se base sur Gecko,Firefox/110.0est le nom du navigateur et sa version.
Ces informations sont très pratiques pour adapter un site web à sa consultation sur smartphone ou ordinateur de bureau. Un site web peut donc prendre plusieurs agencements visuels selon l’équipement qui y accède.
➡ La question en vue d’une identification est donc : est-ce suffisant pour identifier de manière unique cet équipement ? Si oui, on peut alors recouper ses différentes visites sur les sites web et ainsi établir un profil. C’est souvent insuffisant, et des techniques supplémentaires sont nécessaires.
Les données générées
Même si les situations précédentes semblent s’apparenter à une sorte de perméabilité d’accès à des données nous concernant, il existe des techniques agressives dont leur seul but est de nous identifier. Et ce qui compte, c’est d’abord d’identifier de manière unique l’équipement que nous utilisons, pour ensuite en faire correspondre un profil d’activité.
Ces techniques sont utilisées pour la vente de publicité ciblée, qui est tributaire des informations humaines telles que le sexe, la localisation, l’âge, le travail, les médias utilisés (réseaux sociaux,…), les centres d’intérêts, les comportements d’achats,…
Ces informations peuvent être statistiquement devinées au long cours, après une analyse statistique de notre activité en ligne sur une durée minimale.
➡ Les méthodes de génération de ces données ne dépendent plus de l’infrastructure réseau ou des protocoles utilisés, mais bien des éditeurs de sites web. La volonté d’identification numérique est le but et ces méthodes les moyens. Cependant tout n’est pas si tranché ; ces méthodes utilisent des principes techniques déjà mis en place dont certaines parties sont utiles voir nécessaires à la navigation.
Les Cookies
Ce sont des fichiers stockés dans le navigateur de l’utilisateur pendant la navigation. Ils existent par site web. Ils peuvent être utilisés pour des fonctions critiques, comme la rétention d’informations d’authentification, la personnalisation du contenu visuel (langue de l’utilisateur,…) ou pour stocker des données non fonctionnelles, simplement liées à l’utilisateur. Ils sont des vecteurs importants du pistage, dans la mesure où beaucoup d’informations de différentes natures peuvent être stockées. Les cookies sont globaux au navigateur ; de ce fait leur contenu est partagé entre tous les onglets.
Ils sont à diviser en deux catégories : les cookies du site sur lequel nous naviguons, et les cookies d’autres sites web – appelés cookies tiers, très souvent publicitaires. À l’heure où cet article est rédigé, les cookies tiers sont voués à disparaitre 17.
À la première visite d’un site web, ce dernier va demander au navigateur de stocker en mémoire certaines informations. Si auparavant nous avons déjà visité ce même site web, alors les données déjà présentes dans ce cookie seront traitées et mises à jour.
Chaque site web qui utilise des cookies est juridiquement censé nous en avertir et nous laisser le choix du pistage, nous laisser le choix ou non de stocker ces informations que les sites nous font enregistrer. C’est pour cela que nous voyons apparaitre ce type de bandeau lors de nos navigations web.
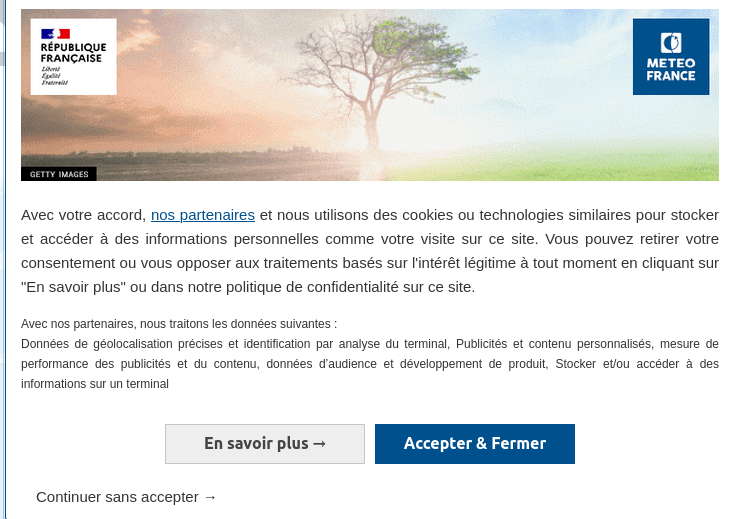
À titre d’exemple, en navigant sur un site de sport, je pourrais consulter la page sportive de ski, puis consulter le site de prévisions météo. Si les deux sites web intègrent un mécanisme de publicité ciblée, je pourrais voir apparaitre des publicités pour l’achat de skis sur le site de prévisions météo. Mais tout dépend de la nature des données enregistrées à mon insu qui révèlent mon comportement en ligne, et de la manière dont elles sont traitées.
➡ En tant qu’utilisateur on ne maîtrise pas le rôle des cookies : authentification, tracking,… Seuls les développeurs des sites web activent les cookies en fonction de leurs besoins. C’est bien sûr sans noter qu’un flou semble volontairement laissé de la part des éditeurs de sites sur leur utilisation. En tant qu’utilisateur, savoir comment sont utilisées nos données demande un effort conséquent et n’est pas direct. Il est toutefois possible avec des extensions de navigateur telles que Privacy Badger 18 de désactiver a minima les cookies tiers, qui sont principalement responsables de la publicité en ligne.
Le Fingerprinting
L’idée est de détecter toute information de l’équipement qui peut le rendre unique. On parle alors de fingerprinting. Comme l’explique la CNIL 19, « Le fingerprinting, ou « prise d’empreinte » est une technique probabiliste visant à identifier un utilisateur de façon unique sur un site web ou une application mobile en utilisant les caractéristiques techniques de son navigateur ».
Le site https://www.amiunique.org/ propose une vérification de l’unicité des navigateurs. Voici le résultat pour mon propre navigateur.
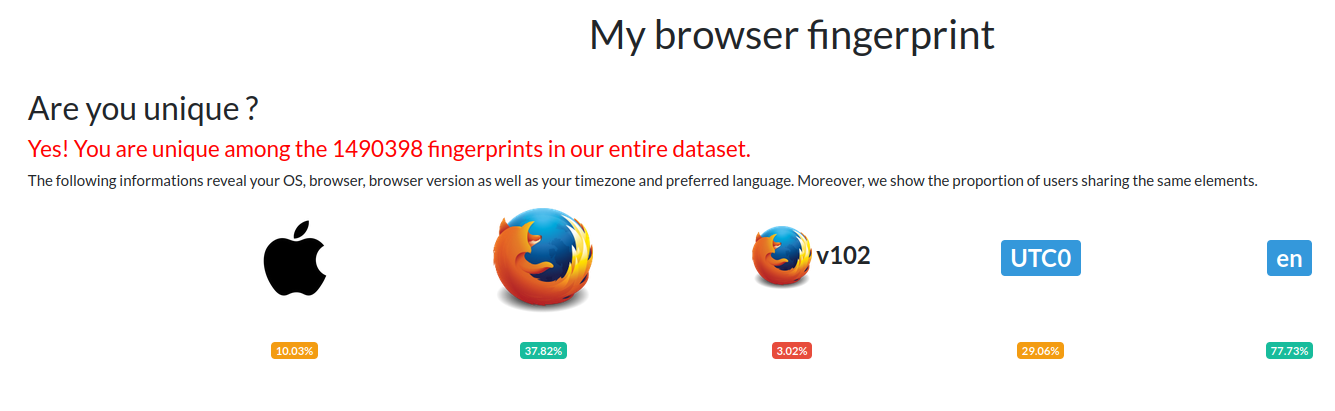
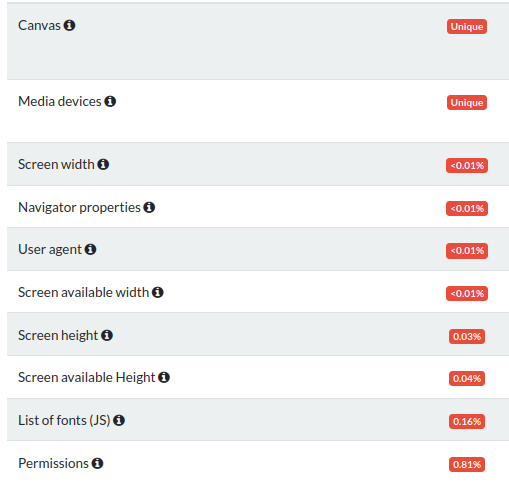
➡ L’énorme quantité de sites web utilisant ces techniques ne nous permet pas d’éviter le suivi et les analyses dont nous sommes la cible. Même si l’utilisation de certaines extensions nous rend unique, certaines sont garantes de notre sécurité et notre confort de navigation. C’est un compromis à faire entre les deux. De manière générale, utiliser le navigateur Firefox suivi des recommandations 20 de Privacy Guides semble un bon point de départ.
Le Single Sign On
Le Single Sign On (SSO) est une méthode permettant l’accès à divers services numérique avec les mêmes identifiants. Cela facilite la navigation de l’utilisateur. On peut par exemple, en utilisant son compte Google, se connecter au site lequipe.fr.
De multiples sites web proposent cette fonctionnalité, qui n’est initialement pas prévue pour du ciblage publicitaire mais pour une simplification de l’authentification en ligne. Dans quelle mesure ces informations d’abonnements sont remontées à l’entreprise Google – dans cet exemple – et sont analysées pour établir un profil utilisateur ?
➡ Le SSO est une méthode qui vise à faciliter la navigation utilisateur sur le web. Par définition, elle empêche les utilisateurs d’avoir de multiples identités sur différents services en ligne. Elle permet d’avoir une vision globale de la navigation utilisateur, et encore une fois, tout dépend du traitement de nos données et de l’écosystème associé.
Résumé
Pour résumer, on peut lister les différents points d’attention argumentés ici et les informations personnelles qui leurs sont liées. Cette liste est non-exhaustive, il existe d’autres moyens de tracer les utilisateurs, notamment en se tournant vers les écosystèmes présents sur les smartphones.
| Composant technique / Méthode | Informations liées |
|---|---|
| Connexion IP | Identité réelle, la position géographique |
Connexion HTTP | Identité numérique, suivi des noms de domaines : profiling |
Connexion HTTP | Identité numérique, informations du navigateur et du système d’exploitation |
| Cookies | Identité numérique, suivi du comportement des utilisateurs |
| Fingerprinting | Identitification unique du navigateur |
| Single Sign On | Identité numérique, suivi du comportement des utilisateurs |
Si un service en ligne nécessitant vos informations personnelles vous piste, le lien entre identité réelle et numérique peut être établi.
Se protéger
Protection juridique
Depuis le mois de mai 2018 21, une législation est entrée en vigueur au sein de la juridiction européenne. Plus connu sous le nom du Réglèment Général de la Protection des Données (RGPD) ce texte apporte certains droits de regard à l’utilisateur de services numériques, si ce service utilise ou enregistre des données à caractère personnel 22.
Le règlement s’applique à tous les organismes établis sur le territoire de l’Union Européenne, mais aussi à tout organisme implanté hors de l’UE mais dont l’activité cible directement des résidents européens.

➡ On peut donc faire valoir ses droits au nom de la réglementation RGPD, et contacter les entreprises pour récupérer les données qu’elles ont nous concernant, voire même en supprimer l’intégralité.
Protection technique
Des solutions permettent de diminuer la perméabilité d’accès à nos données. Même si l’anonymat complet n’est pas atteignable et que la différence doit être faite entre sécurité et confidentialité, un champ des possibles reste ouvert.
L’anonymat est atteint lorsque l’identité n’est pas divulguée au cours d’un échange d’information et qu’on ne peut remonter à une personne. La sécurité s’attarde sur la véracité des interlocuteurs et l’intégrité des informations échangées, tandis que la confidentialité assure que seuls les interlocuteurs aient accès aux informations.
Connexion IP
Pour obfusquer notre position géographique, on pourra citer les réseaux privés virtuels (ou VPN). L’ordinateur (1) se connecte à une machine distante (6) et y redirige sa navigation. C’est un relai qui se connecte au site web consulté (4). Il peut se situer à l’autre bout de la planète, ou dans un pays spécifique, pour éviter la censure par exemple.
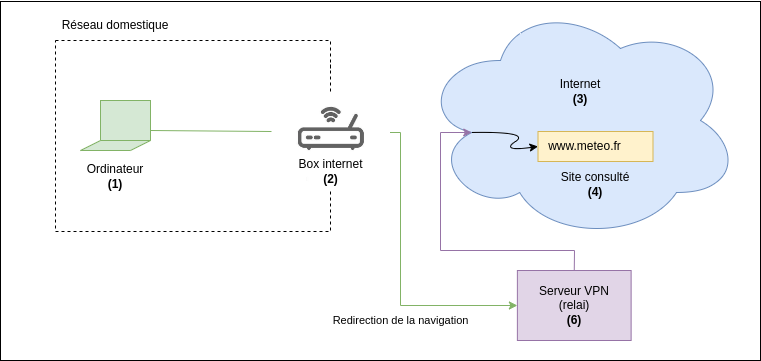
Les échanges se veulent chiffrés entre l’ordinateur (1) et le relai (6), puis les connexions entre le relai et le site web consulté (4) seront chiffrées si le site web propose un mécanisme de chiffrement.
Du point de vue du site web, c’est le relai qui se connecte et donc ce sont ses informations de connexion qui sont analysées : fournisseur d’accès, pays, région, ville… Les demandes de correspondance DNS sont généralement aussi relayées.
➡ On ajoute un relai entre le site web et notre ordinateur (1) : nous ne sommes pas la cible du pistage par adresse… Mais nous faisons confiance à ce relai, qui lui sait qui nous sommes et à quel site web nous souhaitons accéder.
Noms de domaines
Rediriger sa connexion par un serveur VPN (6) permet de ne pas lier les demandes de correspondances (les requêtes DNS dans le jargon) avec l’adresse IP de notre box (2). Cependant, il n’est parfois pas possible de passer par un service VPN. Dans ce cas, on peut proposer de configurer son ordinateur (1) ou sa box (2) de manière à ce que les demandes de correspondance soient faites à des serveurs DNS de confiance, en évitant par exemple ceux de nos fournisseurs d’accès internet.
Voici un post de blog 23 qui propose des adresses de serveurs DNS que l’on peut considérer de confiance.
➡ Nous sommes obligatoirement tributaires du fonctionnement DNS. Pour ne pas être profilé, on peut espérer faire ces requêtes DNS à des serveurs qui ne font pas de profiling.
Sécurité
Le chiffrement est l’un des piliers de la sécurité d’échanges d’informations. Le chiffrement des échanges est primordial pour assurer que les données nous concernant soient acheminées convenablement – sans fuite — au bon interlocuteur. Les mécanismes SSL / TLS en sont garants.
Un certificat est la preuve de l’identité d’un site web, qui est lui-même vérifié par une autorité de certification publiquement reconnue. Un certificat est intriqué avec un nom de domaine. Cette vérification est réalisée naturellement par le navigateur lors de la navigation et il saura nous alerter si elle ne peut se faire.
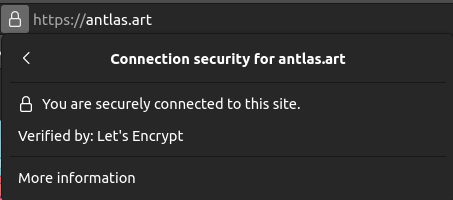
Pour ce site web, c’est Let’s Encrypt 24 qui assure la vérification du site. L’utilisateur peut alors être sûr qu’il échange des données avec seulement antlas.art. En pratique, aucun échange d’informations personnelle n’est demandé par mon site.
➡ il est primordial de s’assurer de la sécurité de la connexion pour les échanges de documents officiels ou documents sensibles. De ce fait, on sait que l’on dialogue avec les bons interlocuteurs et que personne d’autre ne peut accéder aux données en cours d’échange.
User Agent
Il est possible de créer des User Agent factices, en utilisant l’extension Chameleon 25. Les user agents sont donc changés périodiquement et les sites web qui pistent nous voient comme de nous utilisateurs.
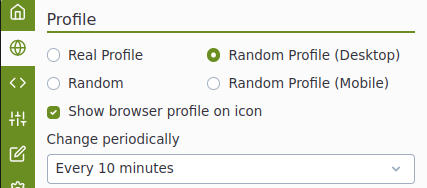
➡ On peut mimiquer des navigateurs, en changer régulièrement. Cela permet de limiter le pistage, qui lui est basé sur ces informations. Cela peut altérer le visuel d’un site web si le user agent simulé est celui d’un smartphone par exemple.
Fingerprinting
Certaines options activables dans les navigateurs permettent de limiter le fingerprinting, mais il est reconnu que le plus d’extensions nous installons, plus notre identité numérique est unique et identifiable.
Firefox 26 tente de bloquer au mieux le fingerprinting.
Concernant la protection contre le fingerprinting, voici les options qui sont disponibles dans Firefox, via about:config accessibles via la barre de recherche. Il faut s’assurer que l’option privacy.resistFingerprinting est mise à true. Elle permet de simuler, bloquer les paramètres testés par les tentatives de fingerprinting.
➡ C’est un bras de fer entre utilisateurs et éditeurs qui ne cesse d’évoluer avec les techniques du moment.
Gestion des cookies
Les cookies seront toujours réécrits lors de la consultation d’un site web. On peut les effacer fréquemment, pour ne pas laisser trop d’informations consultables sur notre comportement. N’oublions pas que certains cookies sont nécessaires aux fonctionnalités des sites web. Les supprimer peut rendre la navigation plus lourde, en nous demandant par exemple de re-configurer les paramètres de langue plus souvent.
Une extension permet de supprimer les cookies de tout onglet du navigateur fermé : Cookies auto delete 27. Elle est très efficace, mais demande de se ré-authentifier assez souvent si l’on a l’habitude de fermer les onglets.
➡ De même, c’est un compromis à faire entre protection et confort de navigation.
Conclusion
➡ Cet article ne fait qu’effleurer le sujet de l’identité numérique, qui mèle partage d’informations voulues et protection du bavardage incessant de nos équipements. De nombreuses ressources sont disponibles sur internet pour se prémunir de cette diffusion constante qui permet de nous identifier personnellement. Un bref panorama a été présenté en décrivant les aspect techniques les plus classiques. Cet article ne fait pas foi, les techniques évoluent et les moyens de protection aussi.
Ce que l’on peut conclure, c’est qu’il existe des moyens de limiter le pistage pendant notre navigation et de rendre difficile l’accès à notre identité numérique. Nous sommes d’une manière ou d’une autre toujours suivis, et la somme de ces moyens peut s’avérer efficace pour la préserver en partie.
Maitriser son identité réelle, c’est-à-dire partager consciemment ses informations personnelles avec attention, reste la première manière de se protéger contre les acteurs malveillants et l’exposition de soi en ligne. Préserver son identité réelle c’est également s’assurer que les échanges de données nous concernant soient sécurisés !
Mais le plus important est de déterminer envers qui nous souhaitons rester discrets, quelles informations on ne souhaite pas dévoiler pour garder au chaud notre identité réelle… et cela passe par lister les outils que nous utilisons, et dans quel but. Les entités ayant accès à notre identité numérique ne sont pas forcément les mêmes que celles qui peuvent accéder à notre identité réelle.
Pour plus d’information sur la vie privée, je vous propose un lien vers Privacy guides !
Notes
Quelques notes au long de cet article :
- L’exemple se concentre sur le web, et donc d’une sous-partie seulement de ce qu’est réellement internet.
- La thématique d’adressage Ethernet (niveau 2 du modèle OSI) a été passée sous silence, en se concentrant sur l’adressage IP (niveau 3).
- Les équipements d’aiguillage sont les routeurs.
- Oui la box, en jouant le rôle de relai entre le réseau local et internet, dispose en vérité de deux adresses, une pour chaque réseau. Souvent accessible à
192.168.1.254dans le réseau domestique. - Le terme « impersonner » signifie faire du
NAT28 dans le contexte de l’exemple.
- Même si la box (2) et les routeurs d’internet (3) relayent la connexion, les routeurs ne vont pas impersonner la connexion. Les routeurs sont là pour aiguiller la connexion, lui faire prendre les bons rails, mais le train part bien de la box.
- Le serveur VPN proposé ici ne joue le rôle que de proxy.
https://www.interieur.gouv.fr/Archives/Archives-des-dossiers/2016-Dossiers/Le-systeme-des-titres-electroniques-securises/Qu-est-ce-que-le-systeme-TES ↩︎
https://www.cnil.fr/fr/les-durees-de-conservation-des-donnees ↩︎ ↩︎ ↩︎
https://www.service-public.fr/particuliers/vosdroits/F34835 ↩︎
https://www.ameli.fr/assure/protection-donnees-personnelles ↩︎ ↩︎ ↩︎
https://c.orange.fr/pages-juridiques/donnees-personnelles.html#durees_conservation ↩︎
https://www.cnil.fr/fr/cookies-et-autres-traceurs/regles/alternatives-aux-cookies-tiers ↩︎
https://www.privacyguides.org/fr/desktop-browsers/#firefox ↩︎
https://www.cnil.fr/fr/reglement-europeen-protection-donnees ↩︎
https://www.economie.gouv.fr/entreprises/reglement-general-sur-protection-des-donnees-rgpd ↩︎
https://www.justgeek.fr/liste-des-serveurs-dns-les-plus-rapides-et-securises-44705/ ↩︎
https://addons.mozilla.org/en-US/firefox/addon/chameleon-ext/ ↩︎
https://www.mozilla.org/fr/firefox/features/block-fingerprinting/ ↩︎
https://addons.mozilla.org/en-US/firefox/addon/cookie-autodelete/ ↩︎
https://culture-informatique.net/cest-quoi-le-nat-cest-quoi-le-pat/ ↩︎