Introduction
Vivant parmi les animaux dans une campagne somme toute classique, il arrive quelquefois que des visiteurs imprévus tournent autour de mon domicile. La nuit ne les rend pas plus polis, et malgré un réveil inopportun, le temps de s’éjecter hors de son lit reste apparemment trop long pour espérer les voir. Est donc venue l’idée d’inlassablement poster quelqu’un sur le balcon, de nuit. Pour des raisons encore obscures, le choix de remplacer cette personne par un détecteur de mouvement fût rapidement adoptée. Le déclenchement de la photo ne doit se faire que lorsque du mouvement est détecté, et que c’est bien un animal qui passe. Bien sûr, se baser sur une image de nuit nécessite une caméra infrarouge.
En alliant une détection de mouvement basique par seuil (basée sur l’intensité des pixels) et une reconnaissance de formes via le projet You Only Look Once1, un petit logiciel pourra voir le jour. La configuration sera bien importante pour apprécier la quantité de données générées : temps d’un évènement, génération en vidéo pour n’avoir qu’un seul fichier,…
Voici donc la présentation de ce petit logiciel que j’ai développé, avec quelques remarques, notamment sur son écosystème global.
Fonctionnement
Ce programme développé en Python détecte de l’activité vidéo et analyse son contenu selon la configuration pour en reconnaitre des formes. Il est également capable de détecter de l’activité audio – sans reconnaissance cette fois.
Il implémente le module argparse pour proposer des options de lancement en ligne de commande. Deux subparsers sont mis en place pour dissocier les options inhérentes au traitement d’image et au traitement audio que le programme propose.
$ python3 -m ir-visualiser -h
usage: __main__.py [-h] [-e EXPORTER] [-E EVENT_DURATION] [-o OUTPUT_DIR]
{video,audio} ...
IR visualiser
positional arguments:
{video,audio} Input kind (video or audio)
options:
-h, --help show this help message and exit
-e EXPORTER, --exporter EXPORTER
Where to export detected images (signal, local), default
local.
-E EVENT_DURATION, --event-duration EVENT_DURATION
Event duration in seconds, default 60
-o OUTPUT_DIR, --output-dir OUTPUT_DIR
Specify an output directory, default ./output.
On appelle le programme sous forme de module Python. Ceci est rendu possible par la présence du fichier __main__.py dans l’arborescence du projet. Cela signifie que chaque développeur a la possibilité de redéfinir sa propre interaction avec la bibliothèque, en faisant un simple import du package (voir section Packaging). L’interaction avec la bibliothèque se fera alors par la classe ir-visualiser.worker et un dict de configuration à lui donner.
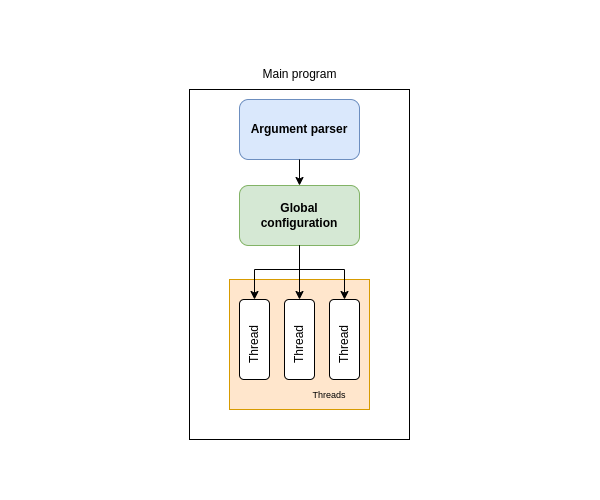
Le programme est divisé en plusieurs parties qui vivent chacunes dans un thread dédié. Chaque module implémente une fonctionnalité unitaire :
- Lecture du flux entrant (d’un périphérique ou d’un flux HTTP),
- Détection de mouvement et reconnaissance des classes d’intérêt (on aurait pu scinder ces deux étapes),
- Traitement après reconnaissance : envoi vers une cible réseau (utilisant Signal ou Telegram) ou vers un dossier local. C’est ce cas d’usage que je décris dans cet article.
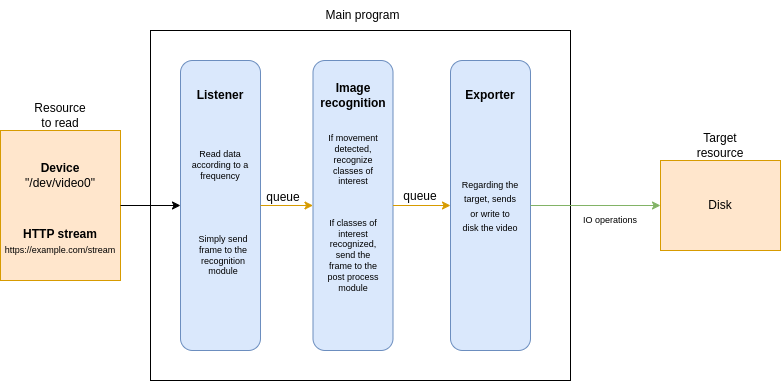
Chaque queue permet une communication thread-safe entre les threads. Chaque queue d’envoi de données (output_queue) est également la queue d’entrée du module suivant (input_queue).
Lecture de flux
La lecture de flux repose sur la bibliothèque OpenCV. La classe dédiée à la lecture du flux vidéo s’instancie avec une URI pointant vers un périphérique local ou un flux distant.
class ImageReader(InterfaceReader):
"""
Class dealing with input flow reading
"""
def __init__(self, video_capture_uri:str="/dev/video0", video_frequency:Optional[int]=None):
super().__init__()
self._capture = None
[...]
def setup(self) -> bool:
"""
Setup the hardware or remote endpoint
"""
try:
self._capture = cv2.VideoCapture(self._video_capture_uri)
except Exception as e:
logger.error(str(e))
return False
[...]
L’envoi vers le module de reconnaissance d’image se fait par l’ajout de l’image en cours de lecture dans sa queue d’envoi (output_queue).
def run(self) -> None:
"""
Continuously read the incoming video stream
and send frames to other thread
"""
while self._running:
if self._read_mode == "fast":
[...]
self._publish(DetectedData(image=frame))
[...]
L’objet DetectedData est une dataclass qui stocke les données d’entrées. À ce stade, son utilisation symbolise une première étape de structuration de données tout au long du process. En effet, le Python reste assez permissif sur l’adjonction d’attributs aux objets, et on pourra même rendre read-only une instance de cette classe en lui appliquant le decorator @dataclass(frozen=True).
@dataclass
class DetectedData:
image: Optional[bytes]=None
video: Optional[byterray]=None
audio: Optional[bytes]=None
metrics: Optional[dict]=None
Reconnaissance de classes d’intérêt
Les classes d’intérêt sont définies par le paramètre en ligne de commande --classes-of-interest. La classe par défaut est person – une personne humaine :
video_parser.add_argument("-C", "--classes-of-interest", help="Specify a class of interest to detect with CNN, default person.", default=["person"], action="store", nargs="+")
Ces classes d’intérêt font partie d’une liste prédéfinie de classes sur lesquelles le modèle YOLO a été entrainé. Cette liste est fixe et contient environ 80 éléments.
Le modèle mathématique YOLO est chargé au démarrage, via la méthode setup.
def setup(self) -> None:
"""
Setup the modalities of image recognition
"""
[...]
# derive the paths to the YOLO weights and model configuration
weightsPath = os.path.sep.join([yolo_path, "yolov3.weights"])
configPath = os.path.sep.join([yolo_path, "yolov3.cfg"])
logger.info("Loading YOLO from disk...")
self._net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
[...]
Le module de reconnaissance d’image bloque alors son exécution sur sa queue de lecture (input_queue) puis le modèle est appelé pour la prédiction.
class ImageRecognition(InterfaceDetection):
"""
Class dealing with image recognition
using deep learning
When specific target is detected, send the image
"""
def __init__(self, capture:str, movement_threshold:int):
super().__init__()
[...]
def run(self) -> None:
"""
Runs the image recognition based on the YOLO weigths
"""
[...]
while self._running:
boxes = []
current_date = datetime.now()
frame = self._input_queue.get()["image"] # FIXME : unsafe
frame = cv2.resize(frame, (640, 360))
blob = cv2.dnn.blobFromImage(
frame,
1 / 255.0,
(416, 416),
swapRB=True,
crop=False
)
self._net.setInput(blob)
start = time.time()
layerOutputs = self._net.forward(ln)
end = time.time()
[...]
Si du mouvement est détecté, et qu’une classe d’intérêt est reconnue dans le contenu de l’image, alors l’image est envoyée au module d’exportation – de stockage. On pourrra choisir d’incorporer dans l’image résultat le tracé des zones détectées.
Sauvegarde des résultats
Sur le même principe, ce thread déclenche une action sur l ‘arrivée de données dans sa queue de lecture. Si le module récupère une image seule dans sa queue de lecture, alors il écrira sur le disque cette image, en png. Dans le cas où il récupère une vidéo, il la sauvegardera alors en mp4.
class WriterModule(threading.Thread):
def __init__(self):
super().__init__()
[...]
def _write_image(self, frame) -> bool:
"""
Write image to disk
"""
res = True
image = None
output_dir = self._config.get_param("general", "output_dir")
suffix = datetime.now().strftime("%Y_%m_%d__%H_%M_%S")
filepath = os.path.join(output_dir, f"image_{suffix}.png")
try:
image = open(filepath, 'wb')
except Exception as e:
logger.warning(str(e))
res = False
[...]
def run(self) -> None:
while self._running:
to_write = self._input_queue.get()
self._process_queue_data(to_write)
Assemblage des modules
La connexion des modules entre eux nécessite leur instanciation préalable et la création de deux queues qui vont être configurées en entrée et sortie.
C’est la classe Worker qui organise cette structure. Cette classe est la classe centrale, véritable colonne vertébrale du programme. Toutes les instanciations annexes des différents composants se font dans cette classe, et le lancement de chaque thread s’y produit.
class Worker(metaclass=Singleton):
def __init__(self):
signal.signal(signal.SIGINT, signal_custom_teardown)
self._config = Configuration()
[...]
self._messaging_queue = Queue(maxsize=100) # création de la queue de lecture du module d'exportation
[...]
def setup(self) -> None:
"""
Setup the objects and queues
"""
[...]
# connexion entre le reader de flux et le traitement d'image
q = Queue(maxsize=100) # création de la queue
reader = ImageReader(video_captures[stream_number], video_frequency)
reader.set_output_queue(q) # le reader de flux configure cette queue comme sa sortie
reader.setup()
recognizer = ImageRecognition(video_captures[stream_number], int(thresholds[stream_number]))
recognizer.set_input_queue(q) # le module de traitement d'image configure cette queue comme sa source, son entrée de données
recognizer.set_output_queue(self._messaging_queue) # configuration de la queue de sortie vers le module d'exportation
recognizer.setup()
[...]
Maintenant que le logiciel a été conçu et développé, attardons-nous plus en détails sur ce qui arrive ensuite : son installation, sa distribution et son lancement.
Chaine de production logicielle
Produire un logiciel signifie le rendre disponible à des tiers. Cela suit plusieurs étapes, dont la gestion de package, l’application de tests et vérifications, la génération de documentation – ou manuel utilisateur, la mise à disposition voire même le déploiement. L’objectif est d’automatiser le plus possible ces étapes qui, une fois opérées séquentiellement, vont fournir un logiciel fiable, documenté et utilisable.
Gestion de package
Packager son logiciel permet de le distribuer facilement. C’est l’objectif ; réduire l’effort à produire pour tester, lancer et utiliser ce logiciel. On parlera de build – de construction de package.
En langage Python, on peut utiliser setuptools 2 pour définir un package et ses attributs. Les paramètres à donner sont nombreux ; dont les principaux sont :
- le nom du package :
name, - le chemin local du package :
packages, - le numéro de version :
version, - l’auteur :
authoretauthor_email, - la liste de dépendances :
install_requires, - les éventuels fichiers statiques à incorporer dans le package :
include_package_dataetpackage_data,
from setuptools import setup
import git
def get_latest_tag() -> str:
repo = git.Repo(".")
tags = sorted(repo.tags, key=lambda t: t.commit.committed_datetime)
latest_tag = "0.0.0"
try:
latest_tag = tags[-1]
except Exception as e:
pass
finally:
return latest_tag
with open("README.md", "r") as readme_fp:
readme_fp = readme_fp.read()
required = []
with open('requirements.txt') as f:
required = f.read().splitlines()
setup(
name="ir-visualiser",
author="antlas",
author_email="",
version=get_latest_tag(),
description="Image detection",
long_description=readme_fp,
include_package_data=True,
packages=["ir-visualiser"],
package_data={"ir-visualiser" : ["yolo-coco/*"]},
python_requires=">=3.6",
classifiers=[
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3 :: Only",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Intended Audience :: Education"
],
install_requires=required,
)
Il est nécessaire dans notre cas d’embarquer le modèle YOLO dans le package lui-même. Il sera statiquement chargé lors des prédictions de reconnaissance d’image.
Il faut porter attention à l’embarquement du modèle dans le package. En effet, cela signifie changer le numéro de version du package à chaque changement du modèle, qui est externe au développement. Pour autant, les cycles de vie des deux éléments sont différents et un changement de version du package devrait répondre à un changement dans son code source. Dans le cadre du MLOps 3, il serait plus approprié de charger à distance le modèle mathématique, voire dans les situations les plus évoluées, d’envoyer les données d’entrée de prédiction aux APIs du serveur de stockage du modèle, et d’en récupérer en réponse les résultats de prédiction.
Le numéro de version est fixé à 0.0.1, suivant la convention major.minor.patch issue du semantic versioning 4. Le numéro patch est incrémenté lorsque des bugs sont résolus, le numéro minor est incrémenté lorsqu’une ou plusieurs fonctionnalités significatives sont implémentées, et le numéro major est incrémenté lorsqu’il y a un changement important, non rétro-compatible par exemple.
Ici, on utilise le module git pour récupérer le numéro de version. Dans l’optique d’avoir une production automatisée, on peut déclencher le packaging automatiquement et ainsi tester le logiciel annoté du bon numéro de version.
Gestion des dépendances
Elle est obligatoire pour proposer une installation automatisée, qui installera toutes les nécessités pour que le package fonctionne. La gestion des dépendances du logiciel peut être assurée par l’utilitaire pipreqs.
$ pipreqs ./ir-visualiser
La liste des dépendances est un bon indicateur structurel ; notamment si elles sont de natures très différentes. Faire par exemple coexister au sein d’un même logiciel ou bibliothèque des dépendances de data science, web et d’opérations bas-niveau témoigne d’un logiciel aux semblants complexes.
D’un point de vue architectural, il est préférable de développer un logiciel dont le domaine d’application est unitaire. Dans notre cas, on aurait pu mettre en place un collecteur de flux, qui met à disposition les flux entrants et vers lequel le module de reconnaissance d’image se connecterait. De ce fait, si la nature de la récupération des flux change, elle n’impacte pas toute la chaine comme c’est le cas ici. Cependant la latence serait plus importante, nécessitant un transfert réseau.
Documentation
On ne répètera jamais assez que la documentation reste un atout central pour la distribution et le partage de logiciel. À notre échelle ici, on peut mettre en place la même procédure de génération évoquée dans ce précédent article.
Docker
Une manière commune de proposer un environnement complet prêt à l’emploi est de compter sur la très répandue plateforme Docker et de mettre à disposition un Dockerfile et un docker-compose.yml. Ces deux fichiers décrivent respectivement le contenu du logiciel déployé (le programme initial et ce qu’il lui faut avec) et la manière de le lancer. Les utilisateurs n’auront plus qu’à intégrer ces fichiers-là et :
- créer l’image Docker issue du
Dockerfile - lancer cette image dans un
containerDocker comme le propose le fichierdocker-compose.yml.
Ici, on se base sur une image Debian. On définit des variables d’environnement par défaut, qui seront passées au programme en argument de ligne de commande. De ce fait, on pourra donner au container Docker une configuration détaillée en lui ajustant ses variables d’environnement.
FROM python:3.9-bullseye
ENV EVENT_DURATION 60
ENV OUTPUT_DIR /var/lib/ir-visualiser
ENV VIDEO_CLASSES_OF_INTEREST "person bird"
ENV VIDEO_CAPTURE "/dev/video0"
ENV VIDEO_FREQUENCY 1
ENV VIDEO_OBJECT_BOXES 1
ENV VIDEO_TO_MOVIE 1
[...]
CMD python -m ir-visualiser --event-duration ${EVENT_DURATION} --output-dir ${OUTPUT_DIR} video --video-cap ${VIDEO_CAPTURE} --video-frequency ${VIDEO_FREQUENCY} --classes-of-interest ${VIDEO_CLASSES_OF_INTEREST} ${VIDEO_OBJECT_BOXES:+--recognition-boxes} ${VIDEO_TO_MOVIE:+--to-video}
Et c’est ce que fait le fichier docker-compose.yml : la section environment permet d’ajuster les variables d’environnement du container, et en coulisse les paramètres du programme. L’interaction est ici simplifiée : on ne se soucie que du container, sans pour autant plonger dans les détails du logiciel en dessous.
version: '2'
services:
ir-visualiser:
image: ir-visualiser:latest
container_name: ir-visualiser
restart: always
cap_add:
- SYS_ADMIN
devices:
- "/dev/video0:/dev/video0"
volumes:
- "./data/:/var/lib/ir-visualiser/:rw"
environment:
- VIDEO_CAPTURE=/dev/video0
- VIDEO_FREQUENCY=1
- VIDEO_TO_MOVIE=
- VIDEO_CLASSES_OF_INTEREST=cat bird
En lançant la commande bash $ docker-compose up dans le répertoire du docker-compose.yml, on pourra lancer le programme de reconnaissance d’image dans un container Docker.
On devra aussi versionner les fichiers
Dockerfileetdocker-compose.yml. Cela signifie que le projet de développement devra également inscrire dans son cycle de vie ces deux produits qui peuvent parfois évoluer sans changement de code source. Exemple : mettre à jour la version d’une dépendance à installer dans leDockerfilene change pas le code source du package Python mais doit être pris en compte dans le projet et peut couvrir une correction de bug.
Testing
Les tests sont une partie importante de la chaine de production logicielle. Ils couvrent de manière non-exhaustive plusieurs aspects :
- la fiabilité du code source (tests unitaires)
- la fiabilité de l’exécution du programme (tests d’intégration)
- la vérification de licences d’utilisation
- la recherche de vulnérabilités
- les rapports de tests.
Sans que cela s’applique complètement à notre cas, on pourra noter la différence entre les tests unitaires et ceux d’intégration. Les tests unitaires se concentrent sur les parties atomiques du code, tandis que les tests d’intégration se concentrent sur la compatibilité d’intégration du programme avec d’autres entités : autres programmes, système d’exploitation,… On teste l’ensemble du produit logiciel, qui peut contenir plusieurs composants.
On peut se tourner vers Python pour certains types de tests, pytest pour les tests unitaires, ou safety pour la détection de vulnérabilités. Son rôle est de scanner l’environnement Python et d’en trouver des failles de sécurité.
$ python -m pip install safety
Voici un extrait de la sortie standard :
$ safety check
+==================================================================================+
/$$$$$$ /$$
/$$__ $$ | $$
/$$$$$$$ /$$$$$$ | $$ \__//$$$$$$ /$$$$$$ /$$ /$$
/$$_____/ |____ $$| $$$$ /$$__ $$|_ $$_/ | $$ | $$
| $$$$$$ /$$$$$$$| $$_/ | $$$$$$$$ | $$ | $$ | $$
\____ $$ /$$__ $$| $$ | $$_____/ | $$ /$$| $$ | $$
/$$$$$$$/| $$$$$$$| $$ | $$$$$$$ | $$$$/| $$$$$$$
|_______/ \_______/|__/ \_______/ \___/ \____ $$
/$$ | $$
| $$$$$$/
by pyup.io \______/
+==================================================================================+
REPORT
Safety is using PyUp's free open-source vulnerability database. This
data is 30 days old and limited.
For real-time enhanced vulnerability data, fix recommendations, severity
reporting, cybersecurity support, team and project policy management and more sign
up at https://pyup.io or email sales@pyup.io
Safety v2.3.5 is scanning for Vulnerabilities...
Scanning dependencies in your environment:
[...]
Using non-commercial database
Found and scanned 76 packages
Timestamp 2023-10-09 11:16:43
6 vulnerabilities found
0 vulnerabilities ignored
+==================================================================================+
VULNERABILITIES FOUND
+==================================================================================+
-> Vulnerability found in certifi version 2022.12.7
Vulnerability ID: 59956
Affected spec: >=2015.04.28,<2023.07.22
ADVISORY: Certifi 2023.07.22 includes a fix for CVE-2023-37920: Certifi
prior to version 2023.07.22 recognizes "e-Tugra" root certificates. e-Tugra's...
CVE-2023-37920
For more information, please visit https://pyup.io/v/59956/f17
[...]
À la suite de tous les tests, on pourra choisir lesquels sont critiques et demandent toujours un résultat positif, et ceux que l’on peut ignorer ponctuellement selon le contexte.
Déploiement
Le déploiement concerne les logiciels voués à être lancés sur des machines, ce qui est notre cas.
Si la machine ou plateforme est déjà existante, alors suivant son type on fera appel à Ansible, on se connectera sur un daemon Docker pour lui envoyer les commandes de création de containers ou de services. De même pour k8s avec ses propres concepts.
k8sa un grosse part de marché dans le monde de l’hébergement et diffère de la plateforme Docker :k8sest unorchestratorqui permet la gestion automatisée des logiciels lancés – et cette problématique est très vaste. Ce n’est pas (complètement) le cas de Docker (petite pensée au mode swarm deDocker enginequi propose des fonctionnalités d’orchestration basiques).
Cette partie-là ne sera pas couverte ici.
Automatisation
On sort du périmètre du logiciel initial pour se tourner vers l’outil de production. En effet, en automatisant au maximum, on augmentera les métriques d’étude de productivité : MTTR , signifiant
Mean Time To Repair: le temps nécessaire moyen pour remettre en état de marche un logiciel, c’est-à-dire qu’il repasse par toutes les étapes de sa production,Mean Time To Recover: le temps moyen que le logiciel en panne nécessite pour être redéployé.
L’objectif est toujours de réduire les temps de panne et le temps de réponse face à un problème rencontré.
Voici une illustration de ces temps issue de la documentation d’Atlassian 5.
Ayant cela en tête, on peut concevoir notre chaine de production, et par exemple commencer par déclencher des procédures relatives aux évolutions du code source. Par exemple, si le code source est tagué, on peut lancer toute la chaine de production.
On sait alors que le MTTR est supérieur ou égal aux temps totaux de la procédure de production : build et de test ici.
Ces concepts-là sont utilisés dans le milieu industriel, et ne sont pas forcément en ligne dans d’autres contextes de travail.
En utilisant Gitlab, on peut créer un fichier .gitlab-ci.yml qui contiendra toutes les étapes de production : testing, reporting, etc.
Voici un exemple reprenant les tests de sécurité décrits ici. Pour plus de clarté, on devrait séparer en deux stages le build et le test.
build_and_test:
image: python:3.9-bullseye
stage: build_and_test
interruptible: true
script:
- apt-get update && apt-get upgrade -y
- apt-get install -y build-essential gcc
- apt-get install -y portaudio19-dev python3-pyaudio python3-opencv
- python -m pip install safety
- python setup.py install --user
- safety check || true
On commence par installer les prérequis, puis le logiciel, puis on scanne ses dépendances. Notons la fin de ligne safety check || true pour que même si des vulnérabilités sont trouvées, la commande retourne 0 (succès) pour ne pas arrêter le stage. De toute façon, on ne va pas régler toutes les vulnérabilités des dépendances… C’est pour cela qu’un stage dédié avec l’option allow_failure: true peut être préférée : on voit que le stage ne réussit pas, mais le pipeline ne s’arrête pas pour autant.
Cette étape de test décrite ici est invoquée si l’une des règles suivantes correspond :
rules:
- if: '$CI_MERGE_REQUEST_TARGET_BRANCH_NAME == $CI_DEFAULT_BRANCH'
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
- if: '$CI_COMMIT_TAG'
- if: '$CI_PIPELINE_SOURCE == "web"'
- si on
mergeune branche sur lamaster - si on
commitune branche sur lamaster - si on
tagune branche - si on lance le pipeline par le portail web.
On peut donc commencer par automatiser son travail et se diriger vers une gestion beaucoup plus rapide.
Conclusion
Après ce tour d’horizon, et à la suite des remarques, de nombreuses pistes d’évolutions sont à suivre, autant pour le développement que pour la gestion du “produit”. Et bien d’autres sujets d’améliorations sont à explorer !
En tous cas, il ne reste plus qu’à disposer la caméra au bon endroit et lancer le container Docker ! Et pour le code, c’est par ici !